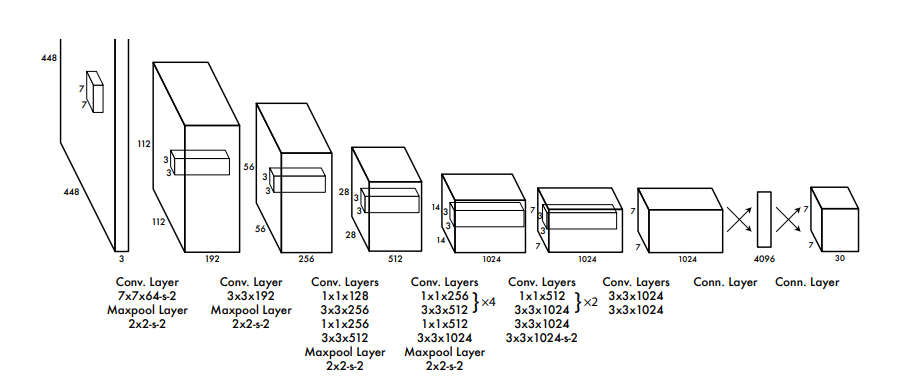
CNN的基础知识可参考笔记:神经网络-CNN系列
R-CNN(Regions with CNN features)是一种将CNN网络应用到目标检测任务的模型。
1. 输入输出
训练输入: \[ T=\{(x_1,g_1), \cdots,(x_N,g_N)\} \] 其中,
- \(x\) 为特征域,\(x_i \in \mathbb{R}^{m \times n \times k},i =1,2,...,N\),表示一个 \(k\) 通道的 \(m * n\) 的图片
- \(g\) 为标签域,\(g_i = \{b_{i1},\cdots b_{in}, cl_i\}\) 包含两部分,\(b_{ij} \in \mathbb{R}^4\) 是目标边框集,\(cl_i \in \mathbb{R}^K\) 是目标的类别集
测试输入 \[ X'=\{x'_1, \cdots ,x'_{N'}\},x'_i \in \mathbb{R}^{m \times n \times k} \] 测试输出: \[ G'=\{g'_1,\cdots,g'_{N'}\},g_i' \in \mathbb R^{5n + K} \]
2. 模型推导
2.1. 基本定义
2014年的论文:Rich feature hierarchies for accurate object detection and semantic segmentation Tech report (v5)
实现代码:https://github.com/rbgirshick/rcnn
一个经典的RCNN结构如下所示
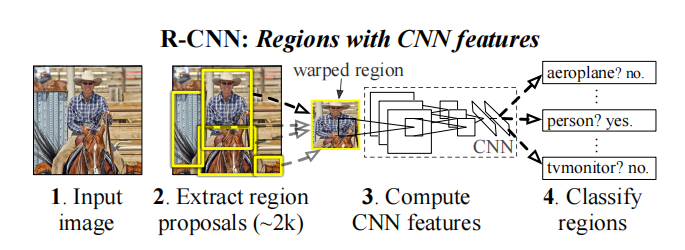
以现在的目光来看,上面RCNN的设计是比较落后的,但既然能作为一个系列的开山鼻祖,其在当时必定是有许多可圈可点的地方。一些主要创新点:
形成日后主流的目标检测模型范式的基本雏形:input(输入,转换)、backbone(主干,特征提取)、neck(脖子?特征增强?)、head(头,预测)
这里想吐槽一下,为什么先脊柱(backbone)后脖子(neck)呢,这是不是有点反常理?
难道外国人是认为从尾巴(tail)或者屁股(bottom)输入,然后从头(head)输出吗?反正我是没太懂这里的逻辑。
RCNN也基本确定了two stage网络的设计范式。two stage网络的基本思想是把网络拆分成分类(类别判断)和回归(位置判断)两个任务进行处理
在当时的目标领域中,分类网络还是以SVM为主,而RCNN引入了CNN网络,从而大大提高了目标检测效果
当时的目标检测算法基本都是滑动取值,即对每个像素都进行一次判断。而RCNN则对图片做两次检测,一次产生启发式的候选区域,一次是对候选区域进行预测,从而大大提升了目标检测的速度(尽管还是很慢)。
下面尝试将网络分成4个部分进行分析
2.2. 学习算法
2.2.1. Input
这一个结构的作用是提取感兴趣目标,作为后续的模型输入
对于每张输入的图片,采用Selective Search 方法,生成1K~2K个候选区域(region proposals/region of interest,Rol)
2013年的论文:Selective Search for Object Recognition
实现代码:https://github.com/AlpacaTechJP/selectivesearch
算法伪代码:

上面算法其实可以简单概括为:先做图像分割,然后做层次聚类,最后对同一类的区域进行合并。
其中,
图像分割。
论文采用的是Efficient Graph-Based Image Segmentation的做法,该算法的处理流程如下:

上述流程可以简单概括为,先将图片用图进行表示,然后寻找最小生成树。
相似度计算。
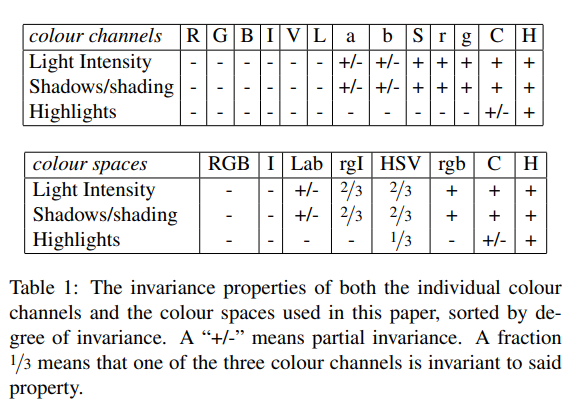
颜色空间(Colour Spaces)互补
没看懂这一步要怎么做,貌似论文只是比较了一下各种颜色空间的特点,并不影响后面的计算
相似度距离(Similarity Measures)计算 \[ s\left(r_{i}, r_{j}\right)= a_{1} s_{\text {colour }}\left(r_{i}, r_{j}\right)+a_{2} s_{\text {texture }}\left(r_{i}, r_{j}\right)+a_{3} s_{\text {size }}\left(r_{i}, r_{j}\right)+a_{4} s_{\text {fill }}\left(r_{i}, r_{j}\right) \] 其中,
- \(s_{\text {colour }}\left(r_{i}, r_{j}\right)=\sum_{k=1}^{n} \min \left(c_{i}^{k}, c_{j}^{k}\right)\) 表示颜色相似度
\(s_{\text {texture }}\left(r_{i}, r_{j}\right)=\sum_{k=1}^{n} \min \left(t_{i}^{k}, t_{j}^{k}\right)\) 表示纹理相似度
- \(s_{\text{size } }\left(r_{i}, r_{j}\right)=1-\frac{\operatorname{size}\left(r_{i}\right)+\operatorname{size}\left({r}_{ {j} }\right)} {\operatorname{size}(\text{ im } ) }\) 表示尺寸相似度
- \(s_{\text{fill} }\left(r_{i}, r_{j}\right)=1-\frac{\operatorname{size}\left(B B_{i j}\right)-\operatorname{size}\left(r_{i}\right)-\operatorname{size}\left(r_{i}\right)}{\operatorname{size}(\operatorname{im})}\) 表示填充相似度
区域合并。
论文中没有介绍是如何进行合并的,个人认为是直接在两个目标框外面套上一个外接框

算法最后还进行了Combining Locations的重排操作,目的是为每个目标框赋予一个优先级,并按优先级排序。具体做法这里就不展开描述了。
接下来,计算每个候选区域与真实目标区域的iou值,最后对所有候选区域resize成一个固定的大小进行输出。
2.2.2. Backbone
这一个结构作用是特征提取
RCNN采用的是AlexNet(网络详细内容参考:神经网络-CNN系列),有一点需要注意的是,在这个阶段,论文中取iou>0.5的区域为正样本(目标区域),反之为负样本(背景区域)。
2.2.3. Neck
这一个结构的作用是通过重排、变换、耦合等手段,将原来的特征向量转换成更”有效“的特征向量
RCNN没有neck结构。
2.2.4. Head
最终的分类预测,一般包含类别预测及目标的位置预测
RCNN使用一个SVM分类器来判别图片的类别(一个one-hot向量),使用一个回归器来预测目标的位置坐标(一个坐标四元组)。
在这个阶段,论文中取iou>0.3的区域为正样本(目标区域),反之为负样本(背景区域)。
到了最终的预测结果输出阶段,还需要使用非极大值抑制(NMS)算法去除多余的候选区域
注:非极大值抑制(Non-maximal suppression,NMS)
合并相似的预测。原来的NMS是用于锚框的情况,这里用于网格的情况。
先从所有锚框中选取一个置信度高的锚框并对其进行标记,然后去掉(抑制)与其IOU值大于 \(\varepsilon\) 的锚框;重复上面步骤,直至所有的锚框都被标记。
会存在两种不一样的做法:
- 先对目标分类再进行NMS融合
- 先进行NMS融合在进行物体目标
理论上,第一种方法更加科学,但实际应用中,为了追求效率,多使用第二种,因为重叠度高但预测为不同类别的情况出现的概率并不高。
注:
- 但会存在一种嵌套识别的任务。如果任务允许一个大的目标里面再嵌套若干个小目标,则需采用第一种做法;如果任务不允许,则需采用第二种做法。
- 另外,还会存在一种”大目标包含小目标“的特殊情况,此时两个目标的IOU值为小目标与大目标之比,如果两者面积相差很大,IOU值会很小,此时小目标就不会被抑制掉
3. 一些改进
原始的RCNN存在很多问题:
尽管RCNN采用Selective Search算法,已经减少了很多的检测次数。但2k次的检测还是很多的,所以RCNN的检测速度依然很慢;
并且RCNN包含的3个模型(1个CNN、1个SVM、一个回归器)都需要单独训练(无法合并成一个损失函数进行求解),并非是一个end-to-end的模型。
针对上诉的两个问题,后面也提出了很多改进的方案。
3.1. Fast R-CNN
2015年的论文:Fast R-CNN
实现代码:https://github.com/rbgirshick/fast-rcnn
模型结构:
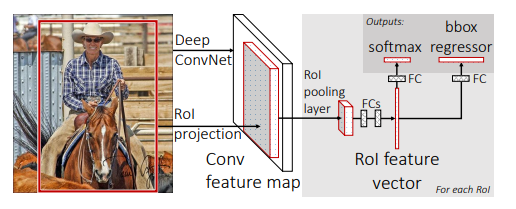
主要改进点:
3.1.1. Input
相关论文:Spatial pyramid pooling in deep convolutional networks for visual recognition
借鉴了SPP-Net(spatial pyramid pooling net)的做法,将目标提取挪到了卷积处理后进行。

SPP的网络结构
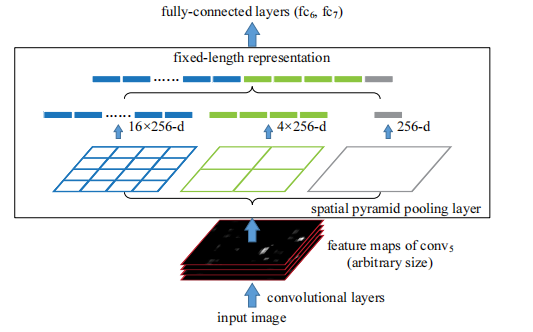
fast RCNN的具体做法是,依然使用Selective Search算法生成候选区域,但这些候选区域并不作为backbone的输入,而是直接投影到backbone输出的feature map上,而backbone的输入则直接使用resize后的图像。这是fast RCNN对vanilla RCNN做出的最大的改进。
其好处是,每张图片由原来需要做n次CNN特征提取,减少为只做一次CNN特征提取。并且本来投影前不重叠的区域也可能因为投影后重叠而被去除,从而减少了需要分类的候选区域。但这个特性是把双刃剑,其意味着对多目标区域的检测效果并不好。
3.1.2. Backbone
采用的是VGG16网络(网络详细内容参考:神经网络-CNN系列)
3.1.3. Neck
由候选区域投影到feature map后的区域是大小可变的,所以需要一种resize的工具,论文中使用一种roi pooling的处理手段,将原本大小不一的输出resize成一个固定的尺寸。
roi pooling的基本思想很简单,先将一个 \(M \times N\) 的区域尽可能地平均分成 \(m \times n\) 个部分,然后再对每个区域求均值。例如,下图是一个 \(7 \times 5\) 的区域resize成一个 \(2 \times 2\) 的区域
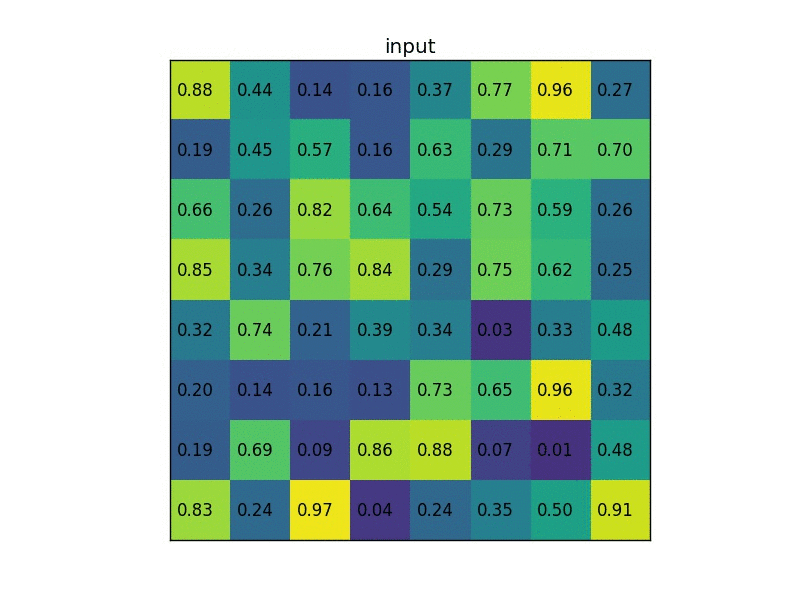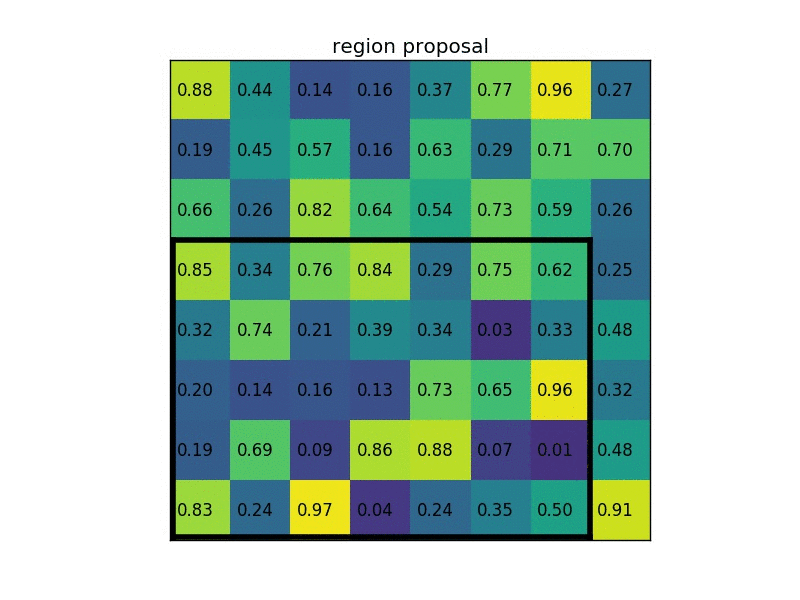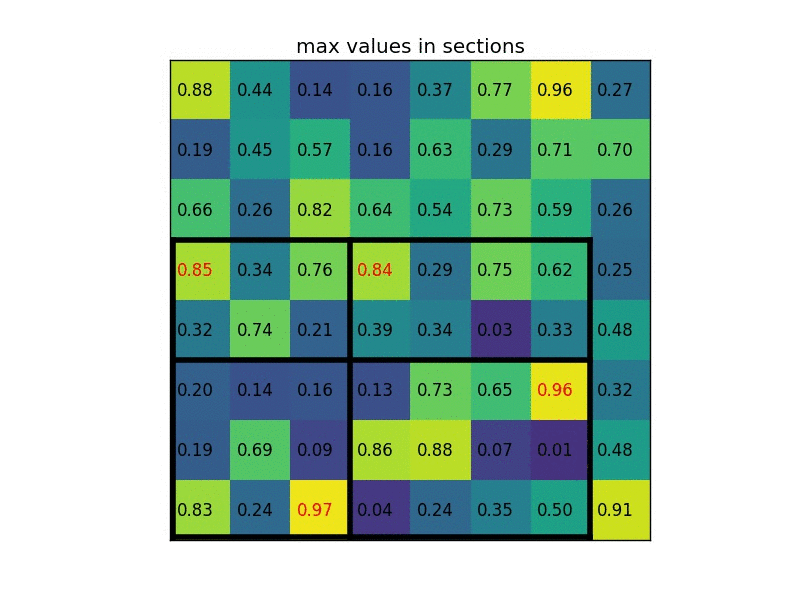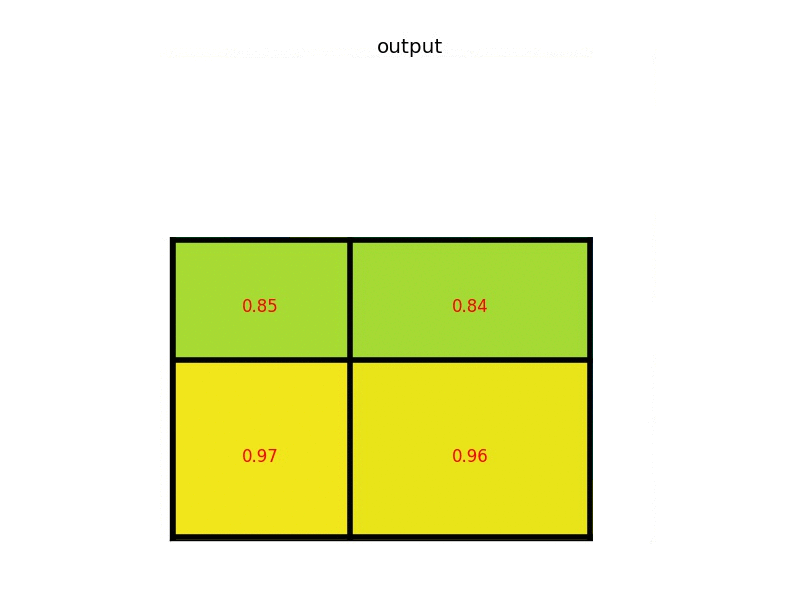
注:传统的pooling的输出是大小可变的,但由于输入一般是大小固定的,所以输出也是大小不变的。
3.1.4. Head
使用两个全连接层分别代替SVM来预测类别及代替回归器来预测位置。
3.1.5. 学习策略
将多个单独的训练任务合并成一个训练任务,并用一个multi-task损失函数表示 \[ L\left(p, u, t^{u}, v\right)=L_{\mathrm{cls}}(p, u)+\lambda[u \geq 1] L_{\mathrm{loc}}\left(t^{u}, v\right) \] 其中,
\(u\) 是目标的真实标签(一个one-hot向量), \(p\) 是对应的预测标签概率,\(v\) 是目标的真实坐标(一个坐标四元组), \(t^u\) 是对应的预测坐标
\(L_{\mathrm{cls}}(p, u)\) 是分类损失,一般就是softmax交叉熵了,即 \(L_{\mathrm{cls}}(p, u) = -u \log p_u = -\log p_u\)
\([u \geq 1]\) 是艾弗森括号(Iverson Bracket),表示满足括号内条件时值为1,否则为0。\(u \geq 1\) 表示正样本,反之则是负样本
$L_{}(t^{u}, v) $ 是位置损失,用到的是smooth L1损失 \[ L_{\mathrm{loc}}\left(t^{u}, v\right) = \sum_{i\in \{x, y, w, h\} } \operatorname{smooth}_{L_{1}}(t_i^u - v_i) \\ \operatorname{smooth}_{L_{1}}(x)= \begin{cases}0.5 x^{2} & \text { if }|x|<1 \\ |x|-0.5 & \text { otherwise }\end{cases} \] 论文指出这种L1损失较L2损失对异常值不敏感,不容易造成梯度爆炸
\(\lambda\) 是超参数,用来控制两个损失的平衡
3.2. Faster R-CNN
NIPS 2015的论文:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
代码实现:
模型结构:
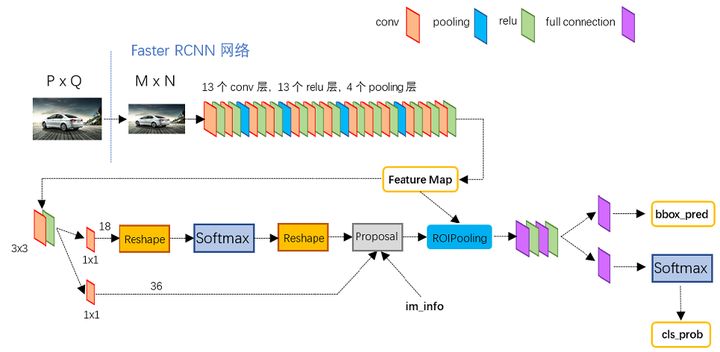
主要改进点:
3.2.1. Neck
在fast RCNN的基础上,提出了使用区域建议网络(Region Proposal Network,RPN)代替Selective Search算法
RPN的应用流程简述如下:
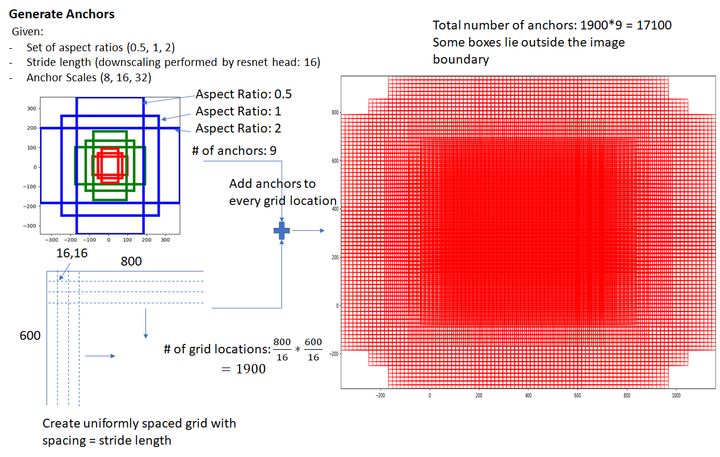
生成锚框。
对于backbone输出的特征图上的每个点,映射回原图片上的点,称为锚点(anchors)。以anchors为中心点,以一定的尺寸划出一些矩形,这些矩形就被称为锚框(anchors boxes)。
按照经验,论文中对每个anchor设立了3种面积(\([8^2,16^2,32^2]\))、3种长宽比(\([1:1, 1:2,2:1]\))共9种不同尺寸的锚框。所以理论上,对于一个 \(m \times n\) 大小的特征图,会产生 \(m \times n \times 9\) 个锚框。
锚框预处理。对于超出边框范围的锚框,一般有两种做法:直接过滤,这种做法的优点是可以减少计算量,一般原本约2W个锚框可以筛选剩余约6k个,缺点是边缘区域不及中心区域敏感;超出部分收缩到图片边缘,然后再过滤掉一些面积太小的锚框。一般选择第二种方案。
划分正负样本集。计算与真实标签的iou值,论文取大于0.7的作为正样本,小于0.3的作为负样本,非正非负样本会被舍弃。
进一步筛选。尽管已经筛掉了很多超出范围及非正非负的锚框,但最终输出的锚框依然很多。所以使用NMS算法,筛选iou>0.7的锚框。这一步剩余约2k个锚框。
另外,在结果预测阶段,一般只取排名靠前的top-N(N一般取300)个锚框。
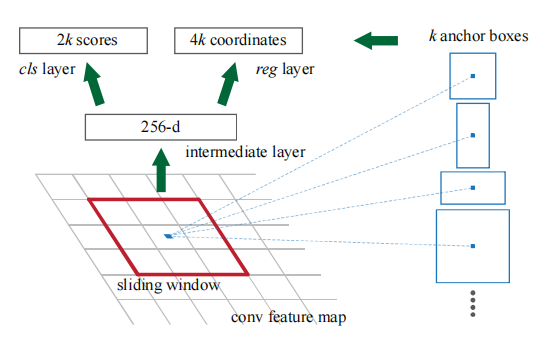
划分任务。先对特征图做一次卷积操作,然后分成两个子任务,一个是分类任务,用来判别锚框是否为正样本;一个是回归任务,用来对锚框进行微调。这里需要注意的是,先做卷积,再分别输入到两个任务中,所以这两个任务只是简单的二分类和回归任务,不需要理会锚框选中区域的特征,只需要根据真实标签给出简单的判断和矫正即可。分类任务的输出矩阵大小为 \(2k\),回归任务的输出矩阵大小为 \(4k\),\(k\) 为锚框的数量
由于只做了一轮卷积处理,所以faster RCNN是one-stage算法
3.3. Mask R-CNN
2018年的论文:Mask R-CNN
实现代码:https://github.com/facebookresearch/Detectron
模型结构:
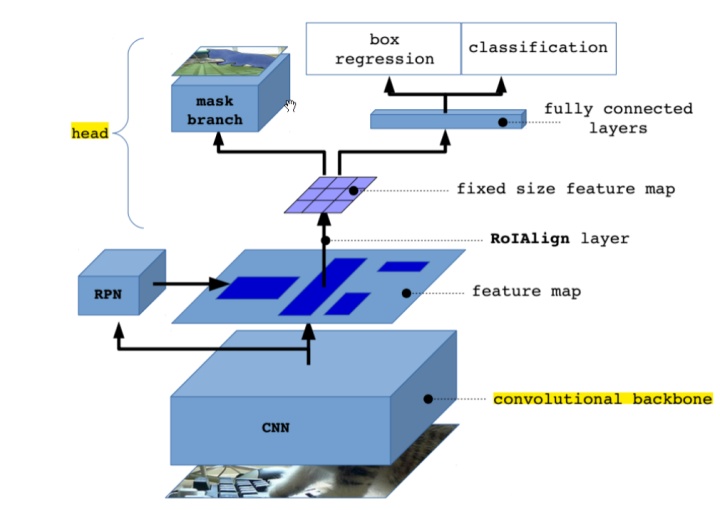
主要改进点:
3.3.1. Backbone
采用的是resnet-FPN架构
CVPR 2017的论文:Feature Pyramid Networks for Object Detection
特征金字塔(Feature Pyramid Networks,FPN)是一种解决不同尺度的目标检测问题的结构,常和CNN网络组合使用。
其基本思想是,对CNN网络中的每一个卷积层输出的特征图,和上一个(如果有的话)卷积层输出的特征图进行耦合,然后进行一次预测输出。由于CNN输出的特征图是从大到小的,就像是一个金字塔,所以就称为特征金字塔。
其简单结构图如下
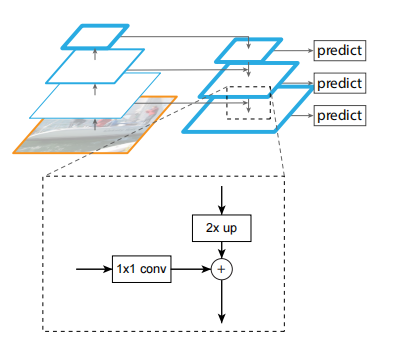
上图中,“2x up”表示上采样,论文中使用最近邻上采样法将特征图的长宽扩大一倍;“1x1 conv”表示卷积核为1的卷积,卷积后特征图的高和上一层特征图的高一致。将两个特征图resize成大小一致的矩阵后,就可以将两者相加,便得到一个新的特征图矩阵。
使用这种结构的好处是,对于层级越深的特征图,语义信息越强,但分辨率也越小,所以对小尺寸目标的检测效果并不好。所以加入上一层具有更高分辨率的特征图,这样既有深层的强语义,又有浅层的高分辨率,从而提高对小尺寸目标的检测效果。对大目标的分析,也如法炮制即可。所以综上,这种结构就可以提高不同尺度的目标检测效果。
重新回到mask RCNN上,是不需要FPN进行预测的,只需要其输出每一个卷积层对应的特征图即可。
然后,除了最深的那个卷积层,其他卷积层对应的特征图都会输入到对应的RPN网络中产生候选区域。
3.3.2. Neck
此前的模型使用的RoI pooling会出现像素偏移的问题。这是因为当RoI投影到特征图时,只是简单的四舍五入取整;然后后续的划分区域的操作,也无法做到完美的均分。由于没有对齐,所以由此计算得到的像素值是不准确的。
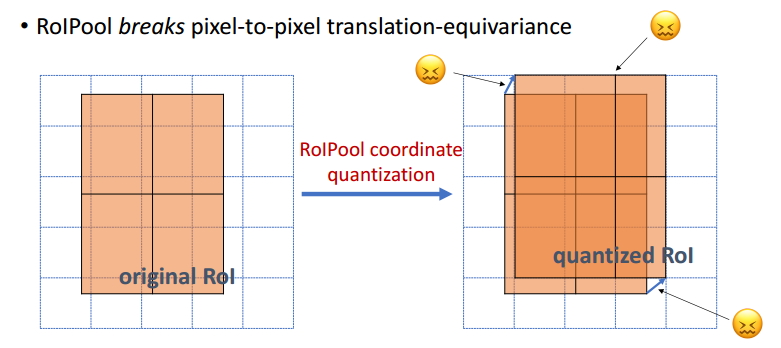
mask RCNN使用RoI Align代替RoI pooling
这里以一个 \(N \times N\) 的RoI区域resize成一个 \(n \times n\) 的区域为例,描述RoI Align的流程为:
将 \(N \times N\) 平均切分成 \(n \times n\) 个单元格
对每个小方块再平均分成 \(k \times k\) 个区域,每个区域的中心点作为一个采样点(在一些实验中,作者发现采样点设为4的效果最好,甚至直接设为1的效果也是不错的)
采用双线性插值法计算每个采样点的值
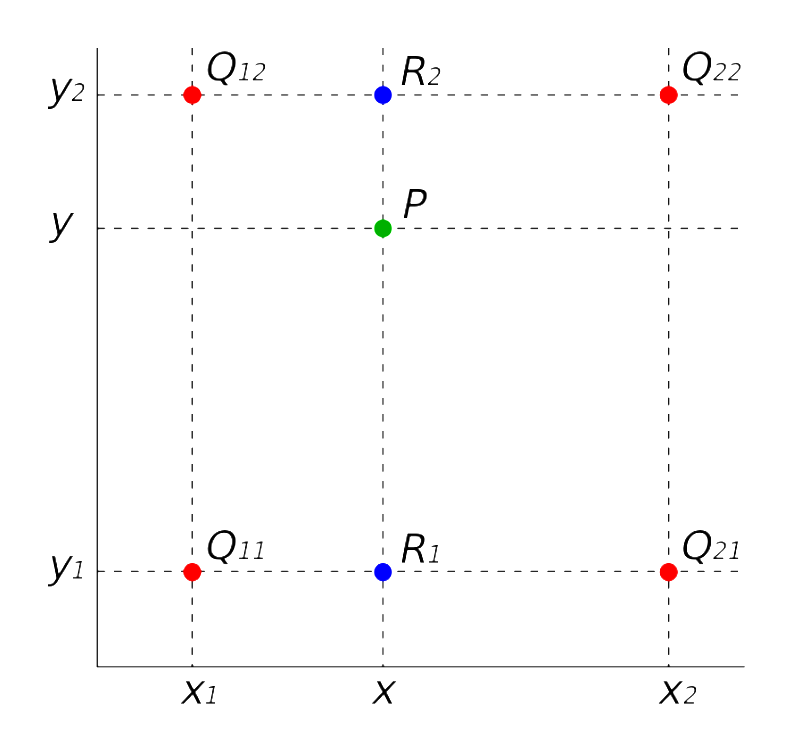
注:双线性插值法,简单来说就是,一个矩形内的一点 \(P(x,y)\) ,P点的坐标与矩形的四个顶点 \(\{ Q_{12}, Q_{22}, Q_{21}, Q_{11} \}\) 存在着线性映射关系
\[
f\left(R_{1}\right)=\frac{x_{2}-x}{x_{2}-x_{1}} f\left(Q_{11}\right)+\frac{x-x_{1}}{x_{2}-x_{1}} f\left(Q_{21}\right) \\
f\left(R_{2}\right)=\frac{x_{2}-x}{x_{2}-x_{1}} f\left(Q_{12}\right)+\frac{x-x_{1}}{x_{2}-x_{1}} f\left(Q_{22}\right) \\
f\left(P\right)=\frac{y_{2}-y}{y_{2}-y_{1}} f\left(R_1\right)+\frac{y-y_{1}}{y_{2}-y_{1}} f\left(R_2\right)
\] 由该映射关系便可计算P点的坐标对单元格内所有的采样点做pooling,得到的值便是该单元格的像素值

3.3.3. Head
除了分类和回归分支,还加入了mask分支,用来完成图像分割任务。mask分支其实就是对每个像素做多分类任务,这是后面图像分割任务的内容,这里也不详细展开了。