YOLO(You Only Look Once,YOLO)是目前最常用的目标检测算法
该算法中文翻译可以简单翻为”一次就好“,英文名称的灵感则来源一句英语的俚语:You only live once
1. 输入输出
训练输入: \[ T=\{(x_1,g_1), \cdots,(x_N,g_N)\} \] 其中,
- \(x\) 为特征域,\(x_i \in \mathbb{R}^{m \times n \times k},i =1,2,...,N\),表示一个 \(k\) 通道的 \(m * n\) 的图片
- \(g\) 为标签域,\(g_i = \{b_{i1},\cdots b_{in}, cl_i\}\) 包含两部分,\(b_{ij} \in \mathbb{R}^5\) 是目标边框集,\(cl_i \in \mathbb{R}^K\) 是目标的类别集
测试输入 \[ X'=\{x'_1, \cdots ,x'_{N'}\},x'_i \in \mathbb{R}^{m \times n \times k} \] 测试输出: \[ G'=\{g'_1,\cdots,g'_{N'}\},g_i' \in \mathbb R^{5n + K} \]
2. 模型推导
2.1. 基本定义
2016年的论文:You Only Look Once: Unified, Real-Time Object Detection
代码实现:https://github.com/pjreddie/darknet
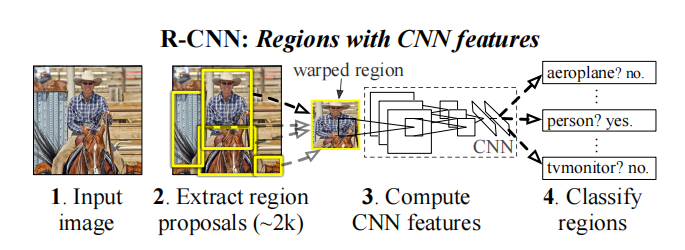
从yolo的名字可以看出,这是一个one-stage策略的算法。在yolo之前主流的目标检测算法是RCNN系列的算法,都是two-stage的算法,即将检测任务的分类(类别判断)和回归(位置判断)两个任务分开处理,而yolo则将这两个任务合并成一个回归任务进行预测。one-stage网络一般比two-stage的速度较快,而准确率较低。
除此之外,yolo最大的创新点在于开创性地提出分而治之的策略,并行地进行多个卷积计算,从而大大地提升了计算速度。
下面先给出yolo的网络结构图
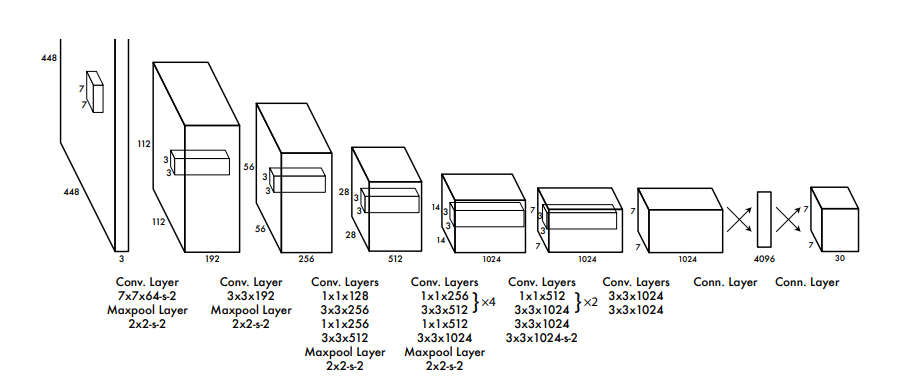
然后还是按照“四段式”结构对其进行分析。
2.2. 学习算法
2.2.1. Input
当时这部分结构的作用是用来提取候选区域,效果比较好的是RPN的提取anchor的做法。但这类算法存在一些的缺点:
- 计算量大。图片很大时,通过滑动取到的分类框自然很多,需要做的分类计算自然也很大。
- 图片大小相关。图片的大小会直接影响到分类框选取的数目,所以对于滑动步长的设置,需要有一个较强的先验知识。
yolo的一大创新就是采用了anchor free的grid base算法。由于不需要提取候选区域,所以yolo就可以只看一次图片就完成检测。
其基本思想是,直接将一个图片均匀地分割成 \(s^2\) 个grid,每个grid负责一个分类任务。即对于输入一个被切分成 \(s^2\) 个区域的图片,模型最终输出一个 \(s \times s \times K'\) 的张量。其中,该张量的最后一维向量表示每个区域的预测标签集合。
其实可以理解为,yolo把每个grid都当成一个候选区域去处理了。
2.2.2. Backbone
一个基于GoogLeNet(网络详细内容参考:神经网络-CNN系列)的分类模型,,另外有一点需要注意的是,backbone网络中的每一层的激活函数都是leaky Relu,计算公式 \[ y = \max(0.1x,x) \]
2.2.3. Neck
首先,作者将坐标四元组定义为 \(\{x, y, w, h\}\) 。其中,\((x,y)\) 表示目标的中心点坐标,\((w,h)\) 表示目标的宽和高
注:取中心坐标是作者根据经验得出的,理论上也可以使用其他任意一个顶点。
考虑到需要和类别向量的取值范围保持一致,还需对其归一化。做法也很简单,对每个值分别除以原始图片的宽 \(w'\) 或高 \(h'\) 即可,即 \(\{x, y, w, h\} \leftarrow \{x/w', y/h', w/w', h/h'\}\) ,可以理解为这一个关于位置的概率值
注:原始论文中是把\((x,y)\) 除以grid的宽和高,即得到了一个相对于grid的概率值。上面采用的是yolov5的做法
由于没有候选区域,为了使模型的效果更好,yolo在四元组的基础上增加了一个变量 \(c\),用来表示四元组输出的置信度,其计算公式如下 \[ c=P(o) * \operatorname{IOU}_{\operatorname{truth} }^{\operatorname{pred} } \]
其中,
\(P(o)\)表示grid中是否有需要检测的目标,有就为1,没有就为0。
\(\operatorname{IOU}_{\operatorname{truth} }^{\operatorname{pred} }\)为交并比(Intersection Over Union)。
注:为了计算简单,有时候也会直接取 \(c = P(o)\)
置信度 \(c\) 和四元组便构成了一个目标的边框集(bounding box) \(b=\{c,x,y,w,h\}\)
如果区域内不存在目标,则直接将bounding box的元素全都置0即可(其实只要将置信度置0即可,其他的位置四元组可以置成任何值)
会存在一个grid存在两个目标的情况。为了提升模型的能力,每个gird可以设置多个bounding box
当然,模型除了预测边框,还得预测每个目标的类别。设标签集为 \(cl\),则每个区域的真实(ground truth)集为 \(g = \{b_1,\cdots b_n, cl\}\)
例如,原论文的例子中,有2个边框集、20个类别,所以最终的真实集大小为 \(30 = 2 * 5 + 20\)
2.2.4. Head
模型的最终输出置信度大于 \(\epsilon\) 的bounding box及其对应的预测类别 \(y\) \[ y = \arg \max_i \left \{ P\left(y_{i} \mid o \right) P(o) \mathrm{IOU}_{\text {pred } }^{\text {truth } } \right \} \] 其中,\(P\left(y_{i} \mid o\right)\) 就是模型对各个类别的预测值
原论文中,还做了一步化简:\(P\left(cl_{i} \mid o\right) P(o) \mathrm{IOU}_{\text {pred } }^{\text {truth } } = P\left(cl_{i}\right) \mathrm{IOU}_{\text {pred } }^{\text {truth } }\)
但我并不理解后面一步化简是怎样得出来的,难道不应该是 \(P\left(cl_{i} \mid o\right) P(o) \mathrm{IOU}_{\text {pred } }^{\text {truth } } = P\left(cl_{i}, o\right) \mathrm{IOU}_{\text {pred } }^{\text {truth } }\) ?
这里会存在一些问题:
- 一个gird可以预测出多个bounding box,就会出现bounding box重叠的情况,这个问题可以使用NMS算法解决
- 由于一个gird只输出一个类别标签,所以模型规定了一个grid只能预测一个类别,这个问题yolo没有办法解决
2.3. 学习策略
yolo的损失函数为 \[ \begin{aligned} \text { loss } &=\lambda_{o} \sum_{i=0}^{S^{2} } \sum_{j=0}^{b} 1_{i j}^{o}\left[\left(x_{i}-\hat{x}_{i}\right)^{2}+\left(y_{i}-\hat{y}_{i}\right)^{2}\right] \\ &+\lambda_{o} \sum_{i=0}^{S^{2} } \sum_{j=0}^{b} 1_{i j}^{o}\left[\left(\sqrt{w_{i} }-\sqrt{\hat{w}_{i} }\right)^{2}+\left(\sqrt{h_{i} }-\sqrt{\hat{h}_{i} }\right)^{2}\right] \\ &+\sum_{i=0}^{S^{2} } \sum_{j=0}^{b} 1_{i j}^{o}\left(c_{i}-\hat{c}_{i}\right)^{2} \\ &+\lambda_{\lnot o} \sum_{i=0}^{S^{2} } \sum_{j=0}^{b} 1_{i j}^{\lnot o}\left(c_{i}-\hat{c}_{i}\right)^{2} \\ &+\sum_{i=0}^{S^{2} } 1_{i}^{o } \sum_{j=0}^K\left(p_{i}(cl_j)-\hat{p}_{i}(cl_j)\right)^{2} \end{aligned} \]
其中, \[ 1_{i j}^{o} = \left \{ \begin{aligned} 1, &\quad \text{obj满足给定条件} \\ 0, &\quad \text{obj不满足给定条件} \end{aligned} \right . \\ 1_{i j}^{\lnot o} = 1- 1_{i j}^{o} \]
按照一些经验,取 \(\lambda_{o}=5,\lambda_{\lnot o}=0.5\)
上式可以分成5部分,分别为中心点损失、宽和高损失、正样本(前景)置信度损失、负样本(背景)置信度损失、类别损失,总体就是位置+置信度+类别损失。每一项的计算都是SSE(sum-squared error),和MSE差不多,前者求和,后者求平均。
有一点需要注意的是,宽和高的损失计算没有直接使用SSE,而是先开平方,再使用SSE。这种做法主要考虑到,对于面积不一样的目标,不能直接使用坐标的偏移量作为真实值与预测值的误差,否则偏移量相等的情况下,大小目标两者计算得到的误差也是相等的,这显然是不合理的。加入平方根可以使得模型对对小尺度的物体更敏感
3. 其他相关工作
vanilla yolo的分而治之的思想保证了其运算速度不会太慢,但由于yolov1可检测的目标有限,模型精度很低。所以后续的一系列的改进都是在保持yolov1的计算速度的同时,提升检测的精率。
个人认为,后续对yolo的改进,在模型结构的改进上,并没有太多亮眼的工作,更多的是缝合了当前应用到工业上的已验证的成熟的trick,其实就是相当于别人给你试了若干个技巧,然后告诉这些技巧管用,你用就行了。而且后面一系列的论文都没有给出损失函数的具体计算公式,其实也增大了对模型的理解难度。
Anyway,不管黑猫白猫,只要好用的都是好猫。
3.1. yolov2
2016年的论文:YOLO9000:Better, Faster, Stronger
由于该算法号称可以检测超过9000中物体,所以又称yolo9000(感觉略中二 =-=)
主要改进的点如下
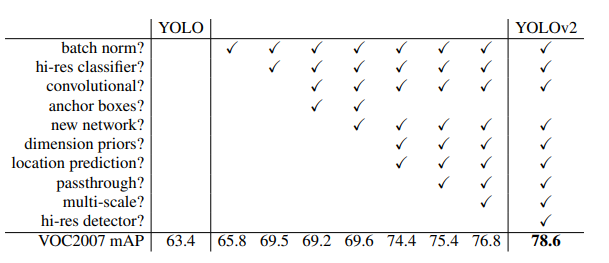
3.1.1. Input
Batch Normalization
现在常用的归一化手段,我也不知道为什么yolov1没有使用上,没啥好说的,略过。
High Resolution Classifier
yolov1的训练集原始图片大小为 224 × 224,训练的时候直接将其增大到 448 × 448 后输入网络中。yolov2则一开始先使用 448 × 448 的图像finetune了10个epoch,使得网络可以预先适应后续高分辨图片的输入,然后使用了 416 × 416 的输入继续进行训练。
Multi-Scale Training
多尺度输入训练策略。每隔一定迭代次数就改变输入图片的大小,使其适应不同大小及分辨率的图片,增强模型的鲁棒性。
具体做法为,每隔10个epoch,就会从一个32倍数(由于下采样的步长为 \(32=416/13\) )的集合 \(\{320, 352, ..., 608\}\) 中随机选取一个值,修改最后检测层的参数,重新训练。
3.1.2. Backbone
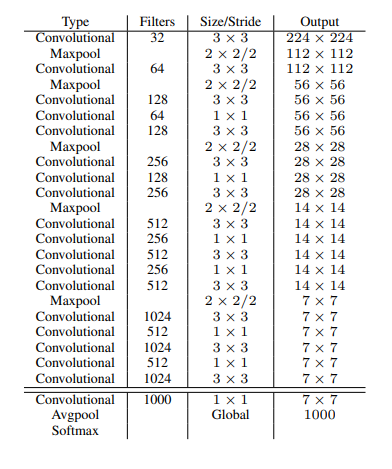
Darknet-19

Darknet-19 = 19个卷积层 + 5个maxpooling层
通过调试出来的经验结构,没啥好说的,用就是了。
3.1.3. Head
anchor box
v1中每个grid只能预测有限个目标,整体预测框也就是百个数量级,v2则重新拾起被v1抛弃的锚框(或者说,其实faster RCNN也才比yolo提出早了半年,作者当时可能还没来得及加入锚框),在Backbone后使用RPN结构替代了全连接层,从而使预测框数量大大增加到千个数量级。
faster RCNN中的RPN结构,其分类预测只是简单的预测背景或前景,v2对其进行扩展,使其可以直接预测类别。
但引入了anchor后,recall是提高了,但mAP反而下降了。猜测造成这个结果的原因是,预测框大大增加,所以召回率很容易就提高了;但需要预测类别增多了,也没有使用太深的网络,所以错误率变高了,导致整体的mAP下降了。
总觉得加了anchor后,yolo丢弃最有创意的grid base部分,失去了灵魂,尽管anchor也是一个很有创意的点子。
dimension clusters
由于anchor的大小设置需要一定的先验知识,像faster RCNN是通过实验设置的。而v2则采用k-means算法,预先对训练集的边框预做聚类,自动选取anchor的大小(原图边框投影到特征图的大小)。
通过实验,在VOC和COCO数据集上,聚类簇数 \(k=5\) 时,聚类效果最佳。
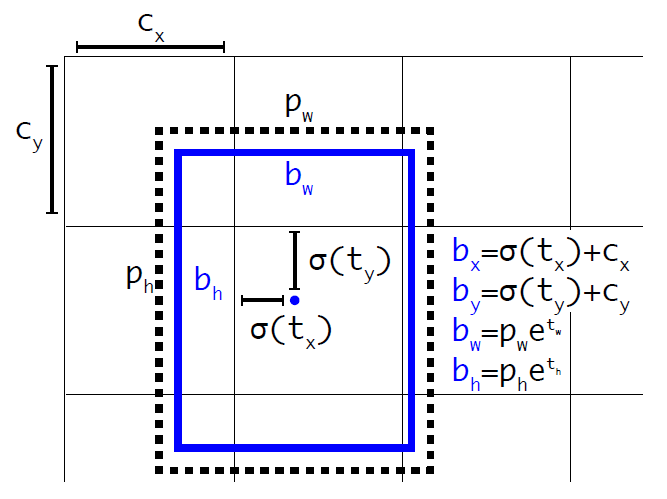
Direct location prediction
假设一个预测边框集为 \(b_t=\{t_c,t_x,t_y,t_w,t_h\}\) ,原始真实边框集为 \(b_a=\{x_a,y_a,w_a,h_a\}\),这里的数值是原始尺寸。对应的原始预测边框集为 \(b=\{t_c,x,y,w,h\}\)
在v1中,存在以下对应关系 \[ x = (t_x w_a) + x_a \\ y = (t_yh_a) + y_a \]
注:原论文该公式有误
由于没有对 \((t_x,t_y)\) 添加限制条件,当 \(t_x>1\) 或 \(t_y>1\) 时,目标会跑到grid外面,即与grid没有交集。
v2认为这是造成模型不稳定的重要因素,所以对输出进行如下变换,将其限制在 \([0,1]\) 区间内
其中,\(b_b = (b_c,b_x,b_y,b_w,b_h)\) 是yolov2的预测边框集,\((c_x, c_y)\) 是grid左上顶点的xy坐标,\((p_w, p_h)\) 是anchor的长和宽, \(\sigma(\cdot)\) 是sigmoid函数
另外,置信度也需要做如下变换 \[ b_c = \sigma (t_c) \]
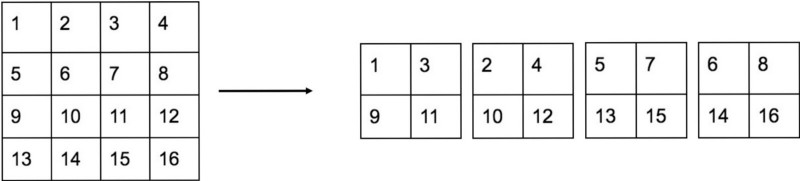
Fine-Grained Features
yolov2认为yolov1最后输出的 feature map尺寸太小了,认为其不利于小尺寸目标的检测。于是借鉴了ResNet网络的identity mappings技巧,提出了passthrough层。
其思想也很简单,既然最后一次的 feature map的尺寸太小,那么就把倒数第二次的 feature map也拼接到最后一次的 feature map上,一并进行预测。
更加具体的,passthrough层先将尺寸较大的feature map分成若干个 \(2\times 2\) 的局部区域,然后从每个区域中抽出一个元素,重新组合成一个feature map,即如下图所示
最后再拼接到较小尺寸的 feature map 上
例如,最后一层的feature map的大小为 \(13 \times 13 \times 512\) ,倒数第二次的feature map的大小为 \(26 \times 26 \times 512\) ,变换后feature map的大小为 \([26 / 2] \times [26 /2] \times [512 \times 4] = 13 \times 13 \times 2048\),最终拼接的feature map的大小为 \(13 \times 13 \times [512+2048]\)
3.2. yolov3
2018年的论文:YOLOv3: An Incremental Improvement
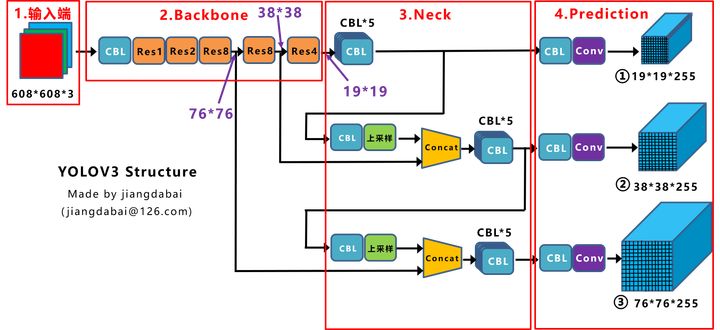
模型结构图:
yolo的原作者Joseph Redmon在v3的论文最后说道,他希望技术应该用于指引宠物行走等对社会有意义的事情上。但他看到现在这些技术大多都用在非法收集个人信息甚至是用于杀人,这是作者不想看到。所以作者后来决定退出计算机视觉的研究
yolo原作者的社会责任感满满的,我对他的观点非常认同,技术应该是纯粹的,并且是应该用于创造更加美好的生活,与诸君共勉。
主要改进点如下
3.2.1. Backbone
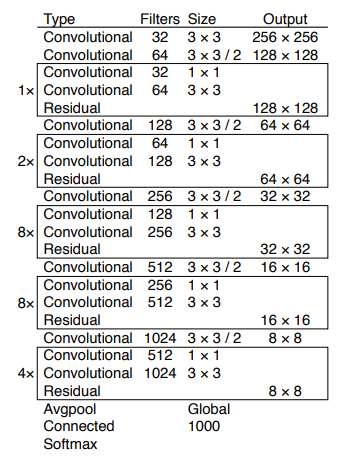
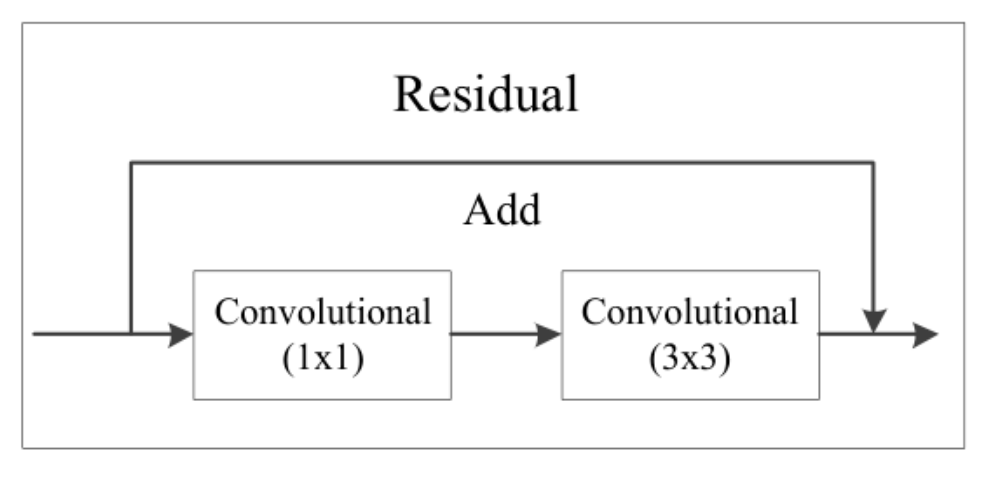
Darknet-53 + FPN + Residual 架构
Darknet-53 =(1+2+8+8+4)个residual结构(一个residual结构由两个卷积层构成)+ 6个卷积层 + 1个全连接层
FPN,这篇笔记以及提及过了,略。
Residual结构是一种类似于Resnet的残差结构
有一点需要注意的是,该网络除了最后一个卷积层,其余的卷积层后都不接池化层
3.3. yolov4
2020年的论文:YOLOv4: Optimal Speed and Accuracy of Object Detection
代码实现:https://github.com/AlexeyAB/darknet
模型结构图:
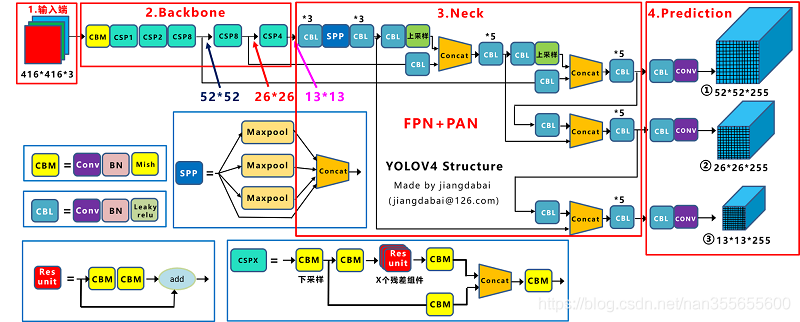
尽管v4并非yolo原作者的研究,但其得到yolo原作者的认可,所以是算作yolo的正统续作。
然后论文里还提了两个概念:
- Bag of freebies(免费包?基础包?),不增加模型复杂度,也不增加推理的计算量的训练方法技巧,来提高模型的准确度,像一些数据增强
- Bag of specials(特赠包?DLC?),增加少许模型复杂度或计算量的训练技巧,但可以显著提高模型的准确度,像SPP、FPN结构等
但由于对其结构理解关联不大,这里就只简单介绍即可。
最后,yolov4感觉更像是一篇综述报告,简述了一下目前目标检测上的工作,然后再说下将其应用到yolo上的效果是怎样的,而具体的实现却一笔带过,只能去翻阅引用的论文及源码才知道具体的实现
主要改进点

3.3.1. Input
Mosaic数据增强
参考CutMix数据增强,将多张图片通过随机缩放、随机裁剪、随机排布的方式拼接成一张图片输入到网络中学习。
采用这种数据增强方式,一般来说会有以下优点:
- 有利于小目标的检测。
- 丰富数据集。对图片的各种变形及拼接,实际上是生成了更多的数据。
- 提高训练速度。训练一张图片实际上就是训练了多张图片。
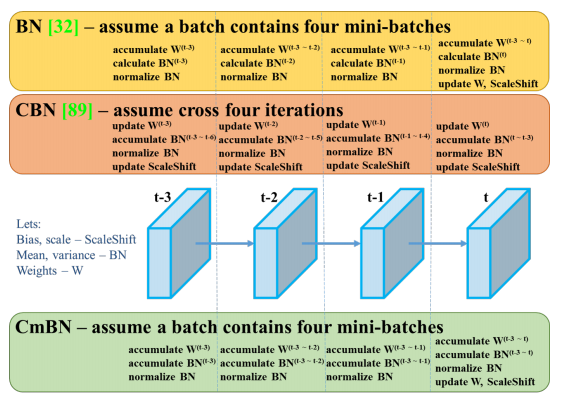
CmBN
交叉小批次正则化(Cross mini-Batch Normalization,CmBN),就是把一个mini-batch(4个数据)当成一个batch去正则化
SAT
参考 https://github.com/AlexeyAB/darknet/issues/5117
自对抗训练( Self-adversarial-training,SAT)就是对输入的图片加上一些噪声,且对部分目标设置错误的分类标签,从而降低过拟合程度


3.3.2. Backbone
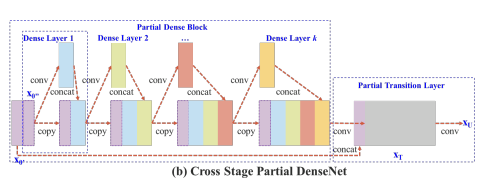
CSPDarknet53
2019年的论文:CSPNET: A NEW BACKBONE THAT CAN ENHANCE LEARNING CAPABILITY OF CNN
CSP(Cross Stage Paritial)其网络结构如下
其实就是由多个残差网络模块拼接组成的结构,但有一个不一样的地方是,只有最开始的 \(x_0\) 会分成两成一部分,一部分参与残差预算,一部分和最终的 \(x_T\) 拼接在一起,相当于在最外层再包了一层残差。
由于只有一部分数据参与了内部的残差运算,所以减少了计算资源
Mish激活函数
相关论文:Mish: A Self Regularized Non-Monotonic Activation Function
采用mish激活函数替换leaky Relu激活函数。mish激活函数的表达公式 \[ y=x \tanh \left(\ln \left(1+e^{x}\right)\right) \]
对比leaky Relu,mish的优点是平滑连续,负值区间更像relu函数,但没有像relu一样完全完全截断。
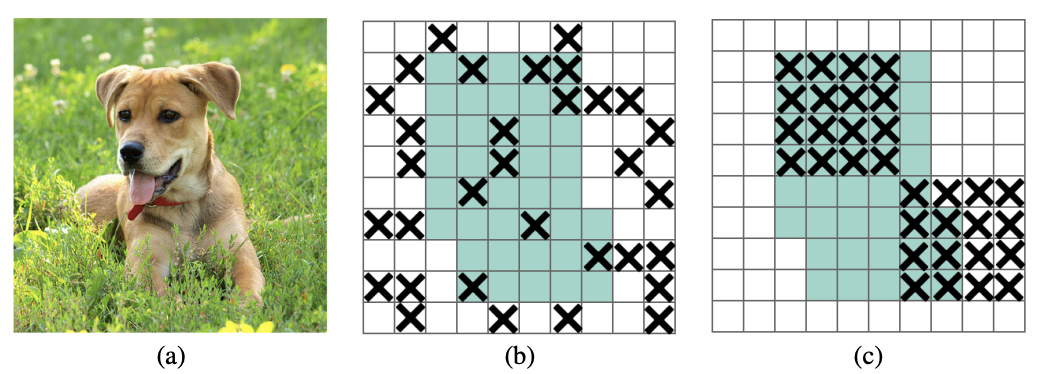
Dropblock
相关论文:DropBlock: A regularization method for convolutional networks
论文认为卷积网络对dropout并不敏感,因为池化其实就已经相当于一次dropout了,所以需要由随机drop像素变为随机drop区域
处理流程伪代码

3.3.3. Neck
SPP
Fase RCNN中已经介绍过,略。
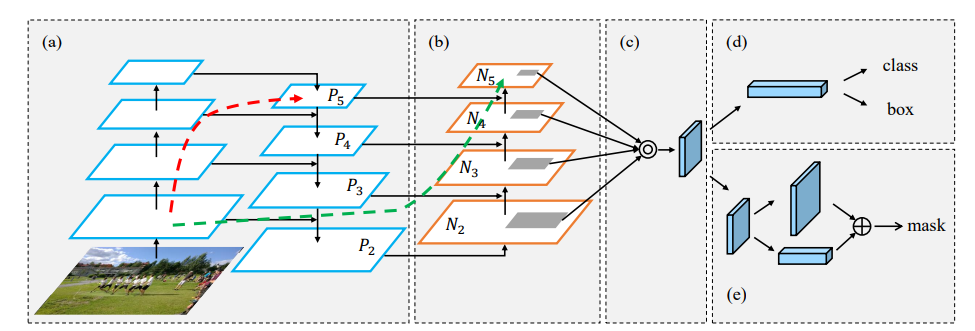
FPN + PAN
相关论文:Path aggregation network for instance segmentation.
路径聚合网络(Path aggregation network,PAN)的网络结构
PAN原本是用于实例分割任务,是对FPN结构的增强。其基本思想是,FPN是up-bottom的,PAN则在FPN后继续接上一个bottom-up的结构,实现数据先自顶向下,再自下向顶的传递,继而强化FPN的能力
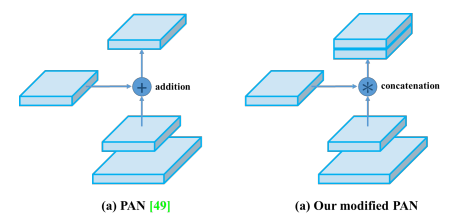
有一点需要注意的是,作者还对PAN的耦合方式进行如下改造
3.3.4. 学习策略
IOU loss
loss计算时,采用CIOU替换IOU。
3.4. yolov5
yolov5只有实现代码,没有对应的论文。
代码实现:
模型结构图:
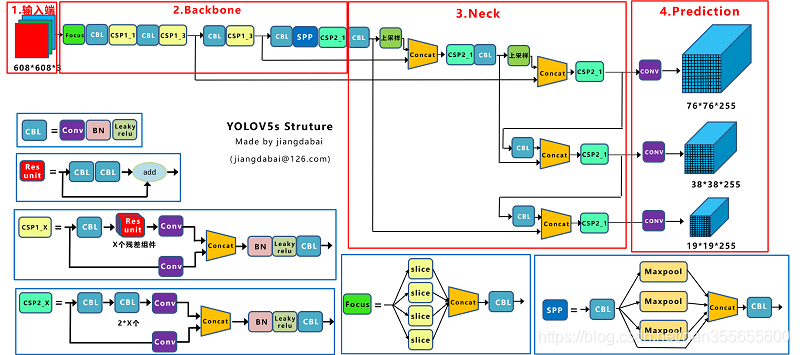
在v4的基础上,再加入一些工程上的技巧,总体结构和v4差不多
由于不是yolo原班人马的作品,并非根正苗红的“yolov”系列,所以还是有很多人不认可其“yolov”的名号。
听说最近美团推出了yolov6,也因为这个原因,被很多人嗤之以鼻。
其实个人感觉这种像抢占注册商标一样去抢占“yolov”的名号,实属没什么必要,欲戴其冠,必承其重。就像yolox都没敢自称是yolovx
主要改进点
3.4.1. Input
自适应锚框计算
就是v2版本的聚类计算锚框大小,区别是v2是单独计算,再单独设置,v5是将其整合到代码里面,每次训练时候就可以自动计算了
自适应图片缩放
使用填充黑边的形式缩放图像,尽可能地保持缩放后的图像长宽比和缩放前一致。
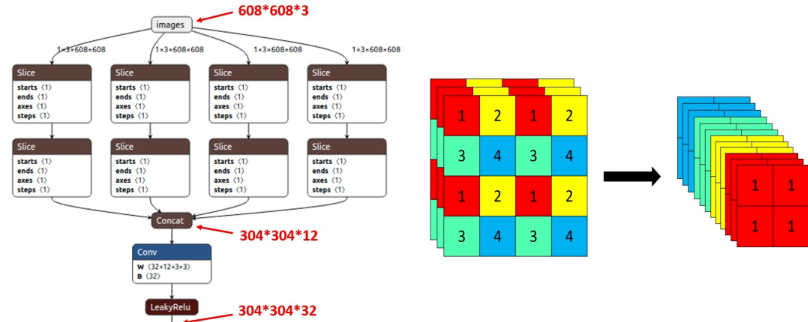
Focus
对图像切片成4份后堆叠,再送进backbone中

3.4.2. Backbone
SiLU激活函数
最新的版本使用SiLU取代了leaky Relu函数,表达公式 \[ y = x \cdot \text{sigmoid}(x) \]
3.4.3. Head
bbox位置预测公式
参考:https://github.com/ultralytics/yolov5/issues/471 \[ \begin{gathered} b_{x}=2 \sigma\left(t_{x}\right)-0.5+c_{x} \\ b_{y}=2 \sigma\left(t_{y}\right)-0.5+c_{y} \\ b_{w}=p_{w}\left(2 \sigma\left(t_{w}\right)\right)^{2} \\ b_{h}=p_{h}\left(2 \sigma\left(t_{h}\right)\right)^{2} \end{gathered} \]
3.4.4. 学习策略
- WarmUp + 余弦学习率衰减策略
3.5. Yolox
2021年的论文:YOLOX: Exceeding YOLO Series in 2021
代码实现:https://github.com/Megvii-BaseDetection/YOLOX
旷视提出的最新的yolo系列的算法,模型结构
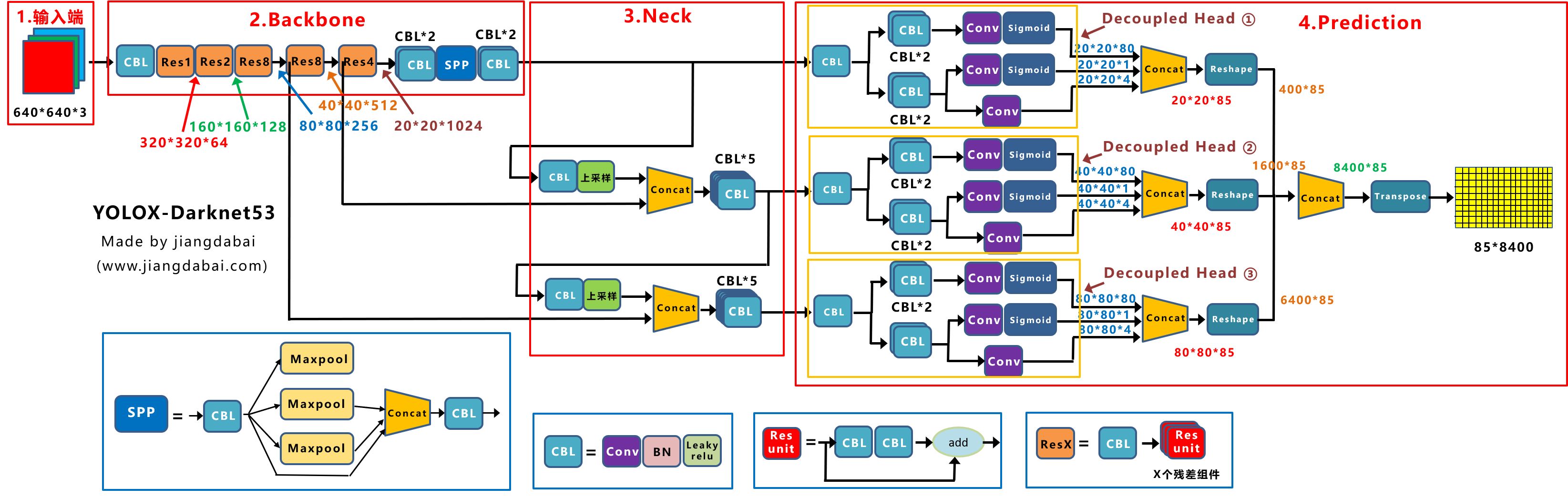
yolox认为yolov4或v5的一些trick用的太过了(其实会不会是yolox在v4或v5的模型上提升的效果不明显,论文不好写,哈哈哈),所以yolox是以yolov3(更准确来说是yolov3-spp)为基础进行改进。
2022, 06, 18记:前几天新闻报道,旷视的算法负责人孙剑逝世了,再看下这篇论文的作者之一就是孙剑,哎,果然天妒英才。
3.5.1. Input
Strong data augmentation
采用了 Mosaic和MixUp两种数据增强(二选一?还是都用了?论文中看不出来),而且再最后的15个epoch会停止使用数据增强。
然后,论文中还指出采用了强数据增强的技巧,在ImageNet数据集上进行预训练,提升效果并不明显,因为所有的模型都是从头开始训练的。
论文中还说,采用了强数据增强的技巧后,之前ImageNet数据集上的预训练模型,在COCO数据集上提升的效果并不明显,所以所有的模型都是从头开始训练的(就是没有采用预训练模型的意思吗?)。
3.5.2. Neck
Anchor-free
anchor base的模型一个很大问题是,需要预测的目标的太多了,而且大多都是负样本。
yolox借鉴了当时的一些像FCOS这样的anchor free的模型,又重新将yolo带回anchor free,我觉得这是yolox的最大的卖点。
做法也很简单,之前backbone输出的特征图,每个像素需要预测n个目标,现在直接只预测一个目标即可
Multi positives
如果只选取目标中心点作为正样本,则会忽略掉很多高质量的预测点,所以yolox将目标中心点附近 \(3 \times 3\) 的区域都作为正样本。
SimOTA
2021年的论文,同为旷视出品:Ota: Optimal transport assignment for object detection.
这是一个动态分配正负标签的算法,其算法伪代码
SimOTA是OTA的简化版,使用dynamic top-k算法替换Sinkhorn-Knopp算法
正负标签分配也是一个很大题目,常用的简单做法是以iou阈值作为标准分配正负样本标签,后面再专门单独开一个专题来讨论吧。

3.5.3. Head
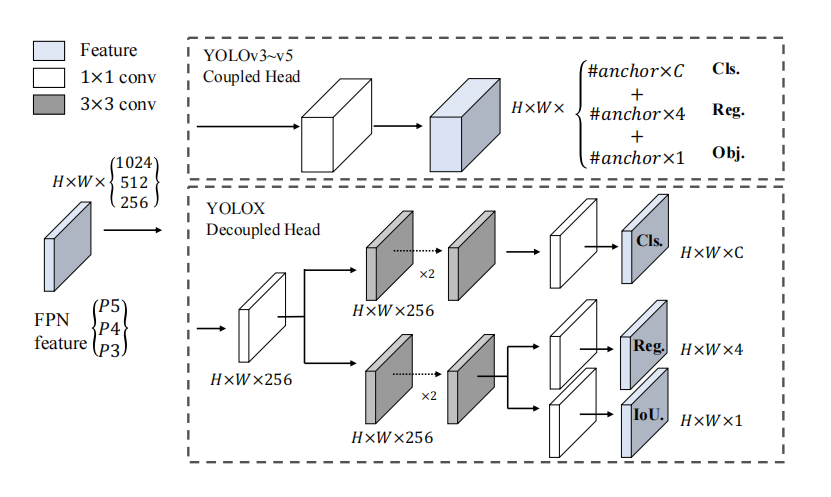
Decoupled Head
解耦头,前面部分和two stage模型很相似,把处理分成了三个部分(下图中从上往下):目标类别、目标位置、置信度。不一样的是,two stage模型每个部分是直接输出,而decoupled head会把三部分输出拼接成一个 \(H \times W \times (C+4+1)\) 的输出,然后再进行统一的处理,重新变回one stage模型
4. reference
https://pjreddie.com/darknet/yolo/
科技猛兽:你一定从未看过如此通俗易懂的YOLO系列(从v1到v5)模型解读 (上)
https://docs.ultralytics.com/
https://iq.opengenus.org/yolov4-model-architecture/
江大白:深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解