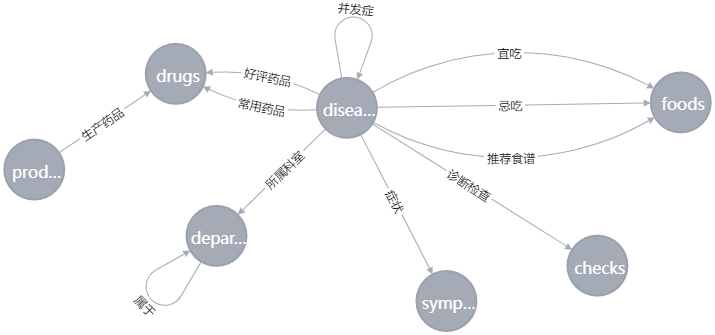
知识图谱的构建可以参考这篇笔记:知识图谱构建实例
这一个实例demo仅基于规则完成问题的匹配,并未涉及任何文本分类或文本生成等算法,所以其适用范围比较窄。
1. 前期准备
导入相关的包
import json
import ahocorasick
from py2neo import Graph准备字典
with open('dict.josn', 'r', encoding='utf8') as f:
words_dict = json.load(f)
# 实体词典
region_words = set()
for v in words_dict.values():
region_words |= set(v)
# 否定词
deny_words = ['否', '非', '不', '无', '弗', '勿', '毋', '未', '没', '莫', '没有', '防止', '不再', '不会', '不能', '忌', '禁止',
'防止', '难以', '忘记', '忽视', '放弃', '拒绝', '杜绝', '不是', '并未', '并无', '仍未', '难以出现', '切勿', '不要',
'不可', '别', '管住', '注意', '小心', '少']
# 问句疑问词词库
question_words_dict = {
'cause' : ['原因', '成因', '为什么', '怎么会', '怎样才', '咋样才', '怎样会', '如何会', '为啥', '为何', '如何才会', '怎么才会', '会导致', '会造成'],
'prevent' : ['预防', '防范', '抵制', '抵御', '防止', '躲避', '逃避', '避开', '免得', '逃开', '避开', '避掉', '躲开', '躲掉', '绕开',
'怎样才能不', '怎么才能不', '咋样才能不', '咋才能不', '如何才能不',
'怎样才不', '怎么才不', '咋样才不', '咋才不', '如何才不',
'怎样才可以不', '怎么才可以不', '咋样才可以不', '咋才可以不', '如何可以不',
'怎样才可不', '怎么才可不', '咋样才可不', '咋才可不', '如何可不'],
'cure_lasttime': ['周期', '多久', '多长时间', '多少时间', '几天', '几年', '多少天', '多少小时', '几个小时', '多少年'],
'cure_way' : ['怎么治疗', '如何医治', '怎么医治', '怎么治', '怎么医', '如何治', '医治方式', '疗法', '咋治', '怎么办', '咋办', '咋治'],
'cured_prob' : ['多大概率能治好', '多大几率能治好', '治好希望大么', '几率', '几成', '比例', '可能性', '能治', '可治', '可以治', '可以医'],
'easy_get' : ['易感人群', '容易感染', '易发人群', '什么人', '哪些人', '感染', '染上', '得上'],
'acompany' : ['并发症', '并发', '一起发生', '一并发生', '一起出现', '一并出现', '一同发生', '一同出现', '伴随发生', '伴随', '共现'],
'food' : ['饮食', '饮用', '吃', '食', '伙食', '膳食', '喝', '菜', '忌口', '补品', '保健品', '食谱', '菜谱', '食用', '食物', '补品'],
'drug' : ['药', '药品', '用药', '胶囊', '口服液', '炎片'],
'check' : ['检查', '检查项目', '查出', '检查', '测出', '试出'],
'belongs_to' : ['属于什么科', '属于', '什么科', '科室'],
'symptom' : ['症状', '表征', '现象', '症候', '表现'],
'cure' : ['治疗什么', '治啥', '治疗啥', '医治啥', '治愈啥', '主治啥', '主治什么', '有什么用', '有何用', '用处', '用途',
'有什么好处', '有什么益处', '有何益处', '用来', '用来做啥', '用来作甚', '需要', '要'],
}
# 问题类型-sql字典表
disease_info_key = ['desc', 'prevent', 'cause', 'easy_get', 'cure_way', 'cure_lasttime', 'cured_prob']
edges_tuple_dict = {
'acompany' : ['diseases', 'diseases', '并发症'], # 疾病并发关系
'not_eat' : ['diseases', 'foods', '忌吃'], # 疾病-忌吃食物关系
'do_eat' : ['diseases', 'foods', '宜吃'], # 疾病-宜吃食物关系
'recommand_eat' : ['diseases', 'foods', '推荐食谱'], # 疾病-推荐吃食物关系
'common_drug' : ['diseases', 'drugs', '常用药品'], # 疾病-通用药品关系
'recommand_drug': ['diseases', 'drugs', '好评药品'], # 疾病-热门药品关系
'production' : ['producers', 'drugs', '生产药品'], # 厂商-药物关系
'check' : ['diseases', 'checks', '诊断检查'], # 疾病-检查关系
'belongs_to' : ['departments', 'departments', '属于'], # 科室-科室关系
'category' : ['diseases', 'departments', '所属科室'], # 疾病与科室之间的关系
'symptom' : ['diseases', 'symptoms', '症状'], # 疾病症状关系
}
# 构建词典
word_type_dict = dict()
for wd in region_words:
word_type_dict[wd] = []
for k, v in words_dict.items():
if wd in v:
word_type_dict[wd].append(k)构建AC自动机(AC自动机原理可参考这篇笔记:数据结构-匹配树)
# 构建ac自动机
region_tree = ahocorasick.Automaton()
for index, word in enumerate(region_words):
region_tree.add_word(word, (index, word))
region_tree.make_automaton()2. 意图识别
def question_classifier(question):
def check_words(words, sentence):
for word in words:
if word in sentence:
return True
return False
# 抽取主体
region_wds = [_[1][1] for _ in region_tree.iter(question)]
stop_wds = [wd1 for wd1 in region_wds for wd2 in region_wds if wd1 in wd2 and wd1 != wd2]
final_wds = [i for i in region_wds if i not in stop_wds]
medical_dict = {i: word_type_dict.get(i) for i in final_wds}
# 判断意图
question_types = []
types = []
for type_ in medical_dict.values():
types += type_
for type_ in types:
for k, v in question_words_dict.items():
if check_words(v, question):
# 已知疾病
if type_ == 'diseases':
# 找食物
if k == 'food':
if check_words(deny_words, question):
question_types.append((type_, 'foods', ('忌吃',), 0))
else:
question_types.append((type_, 'foods', ('宜吃', '推荐食谱'), 0))
elif k == 'drug':
question_types.append((type_, 'drugs', ('常用药品', '好评药品'), 0))
elif k in disease_info_key:
question_types.append((type_, k))
else:
tmp = edges_tuple_dict.get(k, [])
if tmp:
question_types.append((tmp[0], tmp[1], (tmp[2],), 0))
# 已知症状,找疾病
elif type_ == 'symptoms' and k == 'symptom':
question_types.append(('diseases', 'symptoms', ('症状',), 1))
# 已知食物,找疾病
elif type_ == 'foods' and k in ['food', 'cure']:
if check_words(deny_words, question):
question_types.append(('diseases', 'foods', ('忌吃',), 1))
else:
question_types.append(('diseases', 'foods', ('宜吃', '推荐食谱'), 1))
# 已知药品,找疾病
elif type_ == 'drugs' and k == 'cure':
question_types.append(('diseases', 'drugs', ('常用药品', '好评药品'), 1))
# 已知检查项目,找疾病
elif type_ == 'checks' and k in ['check', 'cure']:
question_types.append(('diseases', 'checks', ('诊断检查',), 1))
# 若没有查到相关的外部查询信息,那么则将该疾病的描述信息返回
if not question_types and 'diseases' in types:
question_types = [('diseases', 'desc')]
# 若没有查到相关的外部查询信息,那么则将该疾病的描述信息返回
if not question_types and 'symptoms' in types:
question_types = [('diseases', 'symptoms', ('症状',), 1)]
# 将多个分类结果进行合并处理,组装成一个字典
res_classify = {
'args' : medical_dict,
'question_types': question_types
}
return res_classify3. 生成答案
生成查询语句
def gen_query(res_classify):
entity_dict = dict()
for arg, types in res_classify['args'].items():
for type_ in types:
entity_dict[type_] = entity_dict.get(type_, [])
entity_dict[type_].append(arg)
question_types = res_classify['question_types']
sqls = []
for question_type in question_types:
sql = []
if len(question_type) == 2:
node, attr = question_type
sql += [f"MATCH (m:{node}) where m.name = '{query_name}' return m.name, m.{attr}" for query_name in entity_dict.get(node, [])]
else:
p, q, edges, idx = question_type
query_node = 'n' if idx else 'm'
for edge in edges:
sql += [f"MATCH (m:{p})-[r:{edge}]->(n:{q}) where {query_node}.name = '{query_name}' return m.name, r.name, n.name" for query_name in entity_dict.get(question_type[idx], [])]
if sql:
sqls.append({
'sql' : sql,
'question_type': question_type
})
return sqls定义每个类型的问题输出对应的答句的文本格式
question_answer_dict = {
('diseases', 'symptoms', ('症状',), 0) : '{0}的症状包括:{1}',
('diseases', 'symptoms', ('症状',), 1) : '症状{0}可能染上的疾病有:{1}',
('diseases', 'cause') : '{0}可能的成因有:{1}',
('diseases', 'prevent') : '{0}的预防措施包括:{1}',
('diseases', 'cure_lasttime') : '{0}治疗可能持续的周期为:{1}',
('diseases', 'cure_way') : '{0}可以尝试如下治疗:{1}',
('diseases', 'cured_prob') : '{0}治愈的概率为(仅供参考):{1}',
('diseases', 'easy_get') : '{0}的易感人群包括:{1}',
('diseases', 'desc') : '{0},熟悉一下:{1}',
('diseases', 'diseases', ('并发症',), 0) : '{0}的症状包括:{1}',
('diseases', 'foods', ('忌吃',), 0) : '{0}忌食的食物包括有:{1}',
('diseases', 'foods', ('宜吃', '推荐食谱'), 0) : '{0}宜食的食物包括有:{1}\n推荐食谱包括有:{2}',
('diseases', 'foods', ('忌吃',), 1) : '患有{1}的人最好不要吃{0}',
('diseases', 'foods', ('宜吃', '推荐食谱'), 1) : '患有{1}的人建议多试试{0}',
('diseases', 'drugs', ('常用药品', '好评药品'), 0): '{0}通常的使用的药品包括:{1}',
('diseases', 'drugs', ('常用药品', '好评药品'), 1): '{0}主治的疾病有{1},可以试试',
('diseases', 'checks', ('诊断检查',), 0) : '{0}通常可以通过以下方式检查出来:{1}',
('diseases', 'checks', ('诊断检查',), 1) : '通常可以通过{0}检查出来的疾病有{1}',
}从知识图谱中搜索答案
def answer_search(sqls, num_limit=20):
final_answers = []
for sql_ in sqls:
question_type = sql_['question_type']
queries = sql_['sql']
answers = []
for query in queries:
ress = graph.run(query).data()
answers += ress
if not answers:
break
answers_type = question_answer_dict[question_type]
if len(question_type) == 2:
node, attr = question_type
desc = []
for answer in answers:
if isinstance(answer[f'm.{attr}'], str):
desc.append(answer[f'm.{attr}'])
else:
desc += answer[f'm.{attr}']
final_answer = answers_type.format(
answers[0]['m.name'],
';'.join(set(desc[:num_limit])))
else:
if question_type == ('diseases', 'diseases', ('并发症',), 0):
desc1 = [answers['n.name'] for answers in answers]
desc2 = [answers['m.name'] for answers in answers]
subject = answers[0]['m.name']
desc = [i for i in desc1 + desc2 if i != subject]
final_answer = answers_type.format(
subject,
';'.join(set(desc[:num_limit]))
)
elif question_type == ('diseases', 'foods', ('宜吃', '推荐食谱'), 0):
final_answer = answers_type.format(
answers[0]['m.name'],
';'.join(set([answer['n.name'] for answer in answers if answer['r.name'] == '宜吃'][:num_limit])),
';'.join(set([answer['n.name'] for answer in answers if answer['r.name'] == '推荐食谱'][:num_limit]))
)
else:
p, q, edges, idx = question_type
first_node = 'n' if idx else 'm'
second_node = 'm' if idx else 'n'
final_answer = answers_type.format(
answers[0][f'{first_node}.name'],
';'.join(set([answer[f'{second_node}.name'] for answer in answers][:num_limit]))
)
if final_answer:
final_answers.append(final_answer)
return final_answers4. 结果展示
def main(question):
res_classify = question_classifier(question)
sqls = gen_query(res_classify)
final_answers = answer_search(sqls)
if not final_answers:
answer = '对不起,我无法理解你的问题~'
else:
answer = '\n'.join(final_answers)
return answer
print(main('头痛'))
"""
头痛,熟悉一下:头痛是临床常见症状之一,通常指局限于头颅上半部,包括眉弓、耳轮上缘和枕外隆突连线上的疼痛,病因较复杂,可由颅内病变,颅外头颈部病变,头颈部以外躯体疾病及神经官能症、精神病等引起。
"""
print(main('头痛怎么办'))
"""
头痛可以尝试如下治疗:药物治疗;康复治疗
"""
print(main('头痛吃点啥'))
"""
头痛宜食的食物包括有:鸭蛋;鸡蛋;芝麻;鸭肉
推荐食谱包括有:凉拌莲藕;清拌茄子;紫茄子粥;冬瓜汤;红豆莲藕粥;三鲜冬瓜汤;冬瓜粥;油焖茄子
"""