基于numpy的实现代码传送门
TrAdaBoost是一种基于样本的迁移学习模型
1. 输入输出
迁移学习的域(Domain)表示学习的主体,表达 了数据的特征以及特征的分布。域分为目标域(Target Domain)和源域(Source Domain),目标域指的是要进行学习的域,源领域指的是已有知识的域。而任务(Task)由目标函数和学习结果组成,是学习的结果。
源域输入
\[ S=\{(x_{s_1},y_{s_1}), \cdots,(x_{s_n},y_{s_n})\} \] 其中,
- \(x_s\) 为源域特征域,\(x_{s_i} \in \mathbb{R}^{l},i =1,2,...,n\)
- \(y\) 为源域标签域,\(y_i \in \mathbb R^K\) ,\(K\) 为输出标签集合大小,\(y_i\) 是一个one-hot向量
目标域输入
\[ T=\{(x_{t_1},y_{t_1}), \cdots,(x_{t_m},y_{t_m})\} \] 其中,
- \(x_t\) 为目标域特征域,\(x_{t_i} \in \mathbb{R}^{l},i =1,2,...,m\)
- \(y\) 为源域标签域,\(y_i \in \mathbb R^K\) ,\(K\) 为输出标签集合大小,\(y_i\) 是一个one-hot向量
目标域输出 \[ T'=\{(x'_{t_1},y'_{t_1}), \cdots,(x'_{t_m},y'_{t_m})\} \]
2. 模型推导
2.1. 基本定义
迁移学习一般有以下四种解决方案:
- 基于样本的迁移学习方法(Instance based Transfer Learning)
- 基于特征的迁移学习方法(Feature based Transfer Learning)
- 基于模型的迁移学习方法(Model based Transfer Learning)
- 基于关系的迁移学习方法(Relation based Transfer Learning)
其中,基于样本的迁移学习比较容易实现,而且迁移的知识量最大,应用广泛。其优点是不需要改变目标域的特征空间,可解析性高。
其思想可以概括如下
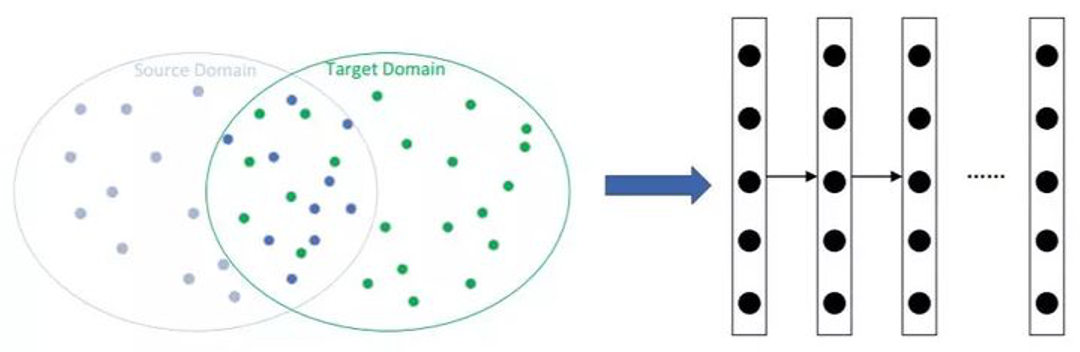
上图中,
- 蓝点集合表示源域,绿点集合表示目标域,两者的交集表示源域与目标域相似的点。
- 假定源域和目标域一定存在交集,那么,设法找到两者的交集,然后使用交集数据训练得到一个基分类器。
- 使用基分类器在整个目标域中进行验证,尝试使用目标域的数据对基分类器进行校正,从而达到迁移的目标。
TrAdaBoost在AdaBoost基础上,再融入上述的迁移思想。其核心思想是对源域和目标域区别对待,具体做法为:
将源域与目标域数据混合,训练得到一个基础分类器;
使用该分类器分别对源域与目标域数据进行预测,对于不同的预测结果:
- 对于源域数据:当它们被误分类后,则认为它们是与目标数据很不同的,是一种噪声数据,则降低它们的权重,使分类器忽视其存在。
- 对于目标域数据:当它们被误分类后,则认为他们是难区分样本,则增加它们的权重,使分类器更加注重对它们的区分。
2.2. 学习策略
合并源域和目标域,得到训练域 \(D=\{S,T\} \in \mathbb{R}^{N \times l},N=n+m\)
定义权重 $^{t} ^{N} $,归一化权重 \(\mathbf{p}^{t}=\mathbf{w}^{t} /\left(\sum_{i=1}^{n+m} w_{i}^{t}\right)\)
基于训练域 \(D\) ,以及对应的归一化权重 \(\mathbf{p}^{t}\),训练得到一个基分类器,并使用该分类器预测训练域的标签
计算基分类的预测标签 \(H=\{h_1, \cdots , h_N\}\) 与真实标签 \(Y=\{y_1,\cdots y_N\}\) 的误差。这一步开始体现TrAdaBoost区别对待的思想。TrAdaBoost认为,其误差只来源于目标域,所以只需要计算目标域部分的误差即可,即 \[ \epsilon_{t}=\sum_{i=n+1}^{n+m} \frac{w_{i}^{t} \cdot\left|h_{t}\left(x_{i}\right)-y\left(x_{i}\right)\right|}{\sum_{i=n+1}^{n+m} w_{i}^{t}} \]
更新权重。
对于源域,以一个固定的衰减因子为 \(\beta = 1/(1+\sqrt{2 \ln n / N})\) 减小其权重,降低其在分类器训练中的影响。
对于目标域,将源域产生的误差,以一个作用因子 \(\beta_t = \left(1-\epsilon_{t}\right) / \epsilon_{t}\) 影响目标域,从而影响其对于分类器训练带来的影响。
综上,整体的权重更新公式可以设计成如下所示 \[ w_{i}^{t+1}=\left\{\begin{array}{ll} w_{i}^{t} \cdot \beta^{\left|h_{t}\left(x_{i}\right)-y\left(x_{i}\right)\right|}, & 1 \leq i \leq n \\ w_{i}^{t} \cdot \beta_t^{\left|h_{t}\left(x_{i}\right)-y\left(x_{i}\right)\right|}, & n+1 \leq i \leq n+m \end{array}\right. \] 对于上述的更新公式,由于 \(\epsilon_{t} \in [0,1],0 \leq {\left|h_{t}\left(x_{i}\right)-y\left(x_{i}\right)\right|}\leq 1\),而在正常的训练过程中,\(\epsilon_{t}\) 是不断减小的, 所以\(g(\epsilon_{t}) = \beta_t^{\left|h_{t}\left(x_{i}\right)-c\left(x_{i}\right)\right|}\) 是一个总体呈下降趋势的函数。
当 \(\epsilon_{t}=0\) 时,目标域不再产生误差,即在权重的作用下,目标域都可以正确的分类, 此时,\(g(\epsilon_{t})=1\) ,权值不再更新,算法收敛,训练完成;
特别地,为了防止过拟合,\(\epsilon_{t}\) 需要小于0.5,才会进行权重更新
结果输出。
原论文中,是综合了后一半的分类器的预测结果,对其进行投票,高于一定阈值,则预测为正样本,反之为负样本。决策公式如下: \[ h_{f}(x)=\left\{\begin{array}{ll} 1, & \prod_{t=\lceil N / 2\rceil}^{N} \beta_{t}^{-h_{t}(x)} \geq \prod_{t=\lceil N / 2\rceil}^{N} \beta_{t}^{-\frac{1}{2}} \\ 0, & \text { otherwise } \end{array}\right. \] 但实际应用中,一般只取后一半分类中,分类效果最好的那一个分类器的输出结果,作为最终的预测结果。
算法的整体流程的伪代码如下:

3. 一些调参方案
3.1. 基分类器选取
TrAdaBoost的效果直接由基分类器的性能决定,而且基分类必须支持设置输入权重。
原论文中使用SVM作为基分类,用于文本类任务的迁移。但目前该模型更偏向于用于纯数值型的任务,所以更偏向于选择树模型作为基分类器。
3.2. 初始权重设置
从上面的推导中可以看出,源域的权重是不断变小的,目标域权重是不断变大的。所以,如果初始化时,源域的权重设置过小或目标域权重设置过大,会使得系统错过了最优解,从而无法收敛。
按照经验,有以下初始化方案的参考:
- 源域权重均设为1/n,目标域权重均设为1/m。这样,可以使得源域和目标域的权重均值都为1
- 源域权重均设为1,目标域正样本权重均设为6,负样本权重均设为3。上诉的数值是一个经验值,实际应用中,可以根据数据分布的特性或通过多次训练自由设置。
4. references
Boosting for Transfer Learning