实现代码传送门
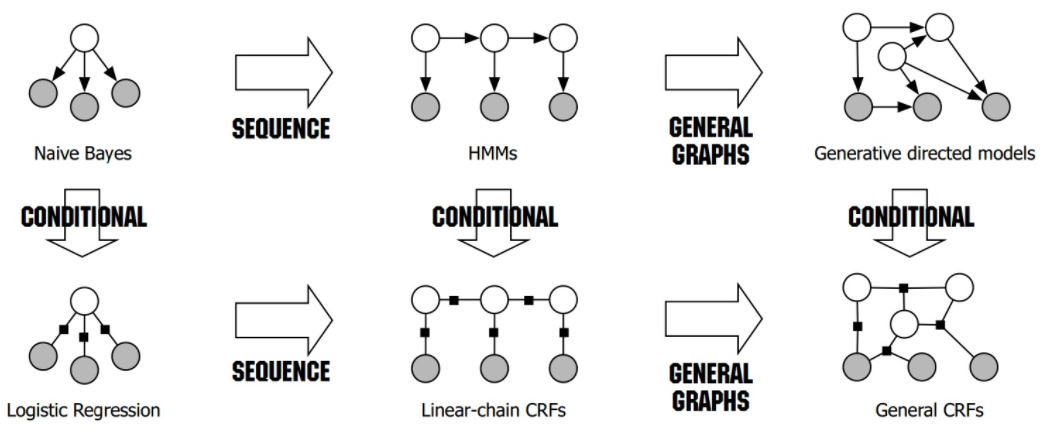
CRF纯原理介绍:标注算法-CRF
1. 数据预处理
训练集采用1998版人民日报词性标注语料,4-tag标注法,但由于纯源码的crf的训练实在太慢了,这里只选择前50句约700个字符进行训练作为演示说明。
2. 构建特征函数
特征函数就是一个规则的集合,该集合包含了状态特征集合 \(s_l = s_{l}\left(y_{i}, x, i\right)\) 和转移特征集合 \(t_k=t_{k}\left(y_{i-1}, y_{i}, x, i\right)\)。
设 \(N\) 是标签类别的总数,\(M\) 是字符集的总数,则状态特征集合的大小为 \(l=N\times M\) ,转移特征集合的大小为 \(k=N^2 \times M\)。为了节省空间及提高检索效率,一般上,集合中只包含训练集出现过的情况。尽管如此,最终得到的特征集仍然很大。
按照上式原理,搭建的特征集取样如下:
char prev_y y
十 0 1
十 -1 1
十 4 1
亿 1 3
亿 -1 3
...上述样例中,char 表示 \(x_i\),prev_y 表示 \(y_{i-1}\),y 表示 \(y_i\),\(y\in\{-1,0,1,2,3,4\}\),其中,\(y=-1\) 表示该特征为状态特征,\(y=0\) 表示 \(i=0\) 时 \(y_{i-1}\) 的取值,\(\{1,2,3,4\}\) 分别表示 4-tag 标记法中的 bmes
3. 构建目标函数的矩阵表示形式
目标函数表示为 \[ m_{i}\left(y_{i-1}, y_{i} \mid x\right)=\exp \left(W_{i}\left(y_{i-1}, y_{i} \mid x\right)\right) \] 其中, \[ W_{i}\left(y_{i-1}, y_{i} \mid x\right)=\sum_{i=1}^{K} w_{k} f_{k}\left(y_{i-1}, y_{i}, x, i\right) \]
其中,\(k\) 为特征集的大小, \[ f_{k}\left(y_{i-1}, y_{i}, x, i\right)=\left\{\begin{array}{l} t_{k}\left(y_{i-1}, y_{i}, x, i\right), \quad k=1,2, \cdots, K_{1} \\s_{l}\left(y_{i}, x, i\right), \quad k=K_{1}+l ; l=1,2, \cdots, K_{2} \end{array}\right. \] 现在,一步步从公式转为实际实现。
首先,初始化为长度为 \(k\) 的零向量 \(w_k\) 。
然后,对于每个 \(x_i\) ,初始化 \(W_i\) 为一个 \([W_{ij}]_{n\times n}\) 的矩阵,其中,axis=0 表示 prev_y ,axis=1 表示 y,n 表示标记集合的大小,特别地,使用 n-tag 标记法时,标记集合的大小为 \(n+1\),因为需要多出一个标记位(为了表示方便,下面称其为开始标记位)用于表示\(i=0\) 时 \(y_{i-1}\) 的取值
\(W_i\) 的计算也很简单,对于转移特征,\(W_{y_{i-1},y_i}=w_{x_i}\),对于状态特征,\(W^{(y_i)}=w_{x_i}\),特别地,设开始标记位为0,当 \(i=0\) 时,应只保留 \(W_{0}\) 的值,当 \(i>0\) 时,应去除 \(W_0\) 和 \(W^{(0)}\) 的值
最后对 \(W\) 取对数即可。
按照上述原理,构建的 \(m_i\) 样例如下:
\(i=0\) 时
[[ 1. 19.2598843 3.35653888 1. 1. ]
[ 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. ]]\(i>0\) 时
[[ 0. 0. 0. 0. 0. ]
[ 0. 1.41366163 1. 1.46362548 5.9805645 ]
[ 0. 1.41366163 1. 3.67782141 5.9805645 ]
[ 0. 5.93660186 1. 0.59619872 59.55394514]
[ 0. 1.41366163 1. 0.59619872 80.68449524]]4. 前向后向算法
这一步主要计算3个值
前向向量 \[ \alpha_{i}^{\mathrm{T}}(x)=\alpha_{i-1}^{\mathrm{T}}(x) M_{i}(x) \] 后向向量 \[ \beta_{i}(x)=M_{i+1}(x) \beta_{i+1}(x) \] 归一化因子 \[ Z(x)=\alpha_{n}^{\mathrm{T}}(x) \cdot \mathbf{1} \] 这一步的迭代过程已经很清晰了,没有什么需要提的地方,有一个需要注意的是,迭代过程中可能会向上溢出,所以需要做溢出处理,但这一步不是必须的,可以省略。
将每一时刻的前向和后向向量按行组合成矩阵形式
序列 1986年 , 初次训练个值计算结果样例如下:
# alpha
[[1.000e+00 1.000e+00 1.000e+00 1.000e+00 1.000e+00]
[0.000e+00 4.000e+00 4.000e+00 4.000e+00 4.000e+00]
[0.000e+00 1.600e+01 1.600e+01 1.600e+01 1.600e+01]
[0.000e+00 6.400e+01 6.400e+01 6.400e+01 6.400e+01]
[0.000e+00 2.560e+02 2.560e+02 2.560e+02 2.560e+02]
[0.000e+00 1.024e+03 1.024e+03 1.024e+03 1.024e+03]]
# beta
[[0.000e+00 1.024e+03 1.024e+03 1.024e+03 1.024e+03]
[0.000e+00 2.560e+02 2.560e+02 2.560e+02 2.560e+02]
[0.000e+00 6.400e+01 6.400e+01 6.400e+01 6.400e+01]
[0.000e+00 1.600e+01 1.600e+01 1.600e+01 1.600e+01]
[0.000e+00 4.000e+00 4.000e+00 4.000e+00 4.000e+00]
[1.000e+00 1.000e+00 1.000e+00 1.000e+00 1.000e+00]]
# Z(x)
4096.05. 训练迭代
采用拟牛顿法
首先看优化目标函数 \[ \min _{w \in \mathbf{R}^{n}} f(w)=\sum_{x} \tilde{P}(x) \log \sum_{y} \exp \left(\sum_{i=1}^{n} w_{i} f_{i}(x, y)\right)-\sum_{x, y} \tilde{P}(x, y) \sum_{i=1}^{n} w_{i} f_{i}(x, y) \] 上式拆成两部分
第二部分比较容易计算,\(\sum_{x, y} \tilde{P}(x, y) \sum_{i=1}^{n} w_{i} f_{i}(x, y)\) 表示每个字符出现的频数与其对应的权值相乘之和
至于第一部分,可以进行如下计算 \[ \sum_{x} \tilde{P}(x) \log \sum_{y} \exp \left(\sum_{i=1}^{n} w_{i} f_{i}(x, y)\right) = \sum_x \log Z(x) \] 其中,\(Z(x)\) 就是上一步步骤中每个序列计算得到的 \(Z\) 值
对应的梯度为 \[ g(w) = \sum_{x,y}\tilde{P}(x)P_w(y\mid x)f(x,y)-E_\tilde{P}(f) \] 同样的分成两部分,第二部分就是每个字符出现的频数,第一部分主要需要计算的是 \(P_w(y\mid x)\) ,这个又分成两个部分
状态条件概率 \[ P\left(Y_{i}=y_{i} \mid x\right)=\frac{\alpha_{i}^{\mathrm{T}}\left(y_{i} \mid x\right) \beta_{i}\left(y_{i} \mid x\right)}{Z(x)} \]
转移条件概率 \[ P\left(Y_{i-1}=y_{i-1}, Y_{i}=y_{i} \mid x\right)=\frac{\alpha_{i-1}^{\mathrm{T}}\left(y_{i-1} \mid x\right) M_{i}\left(y_{i-1}, y_{i} \mid x\right) \beta_{i}\left(y_{i} \mid x\right)}{Z(x)} \]
特别地,为了防止过拟合,可以加入正则项 \(\frac{\sum \|w \|}{\sigma^2}\),非必须,可省略
最后就是进行参数迭代了,这里直接采用 scipy.optimize 的 fmin_l_bfgs_b 方法(方法使用文档参考这里)进行迭代训练,至于源码实现,后面有时间再补吧。
6. 模型预测
采用维特比算法,原理步骤已经很清晰了,没有什么特别难理解的地方,按照原理实现一遍即可
初始化 \[ \delta_{1}(j)=w \cdot F_{1}\left(y_{0}=\text { start }, y_{1}=j, x\right), \quad j=1,2, \cdots, m \]
递推 \[ \delta_{i}(l)=\max _{1 \leqslant j \leqslant m}\left\{\delta_{i-1}(j)+w \cdot F_{i}\left(y_{i-1}=j, y_{i}=l, x\right)\right\} \]
\[ \Psi_{i}(l)=\arg \max _{1 \leqslant j \leqslant m}\left\{\delta_{i-1}(j)+w \cdot F_{i}\left(y_{i-1}=j, y_{i}=l, x\right)\right\} \]
终止 \[ \max _{y}(w \cdot F(y, x))=\max _{1 \leqslant j \leqslant m} \delta_{n}(j) \]
\[ y_{n}^{*}=\arg \max _{1 \leqslant j \leqslant m} \delta_{n}(j) \]
返回路径 \[ y_{i}=\Psi_{i+1}\left(y_{i+1}\right), \quad i=n-1, n-2, \cdots, 1 \]
7. 分词效果展示
['全党', '和', '全国', '各族', '人民', '团结', '一致', ',', '坚持', '党', '的', '领导', ',', '坚持', '马列主义 ', '、', '毛泽东思想', ',', '坚持', '人民', '民主', '专', '政 ', ',', '坚持', '社会主义', '道路', '。']