基于numpy的实现代码传送门
1. 基本定义
给出模型的目标函数 \(J(\theta)\),通过优化算法,数值计算求解出 \[ \theta = \arg \min_{\theta} J(\theta) \]
2. 作图说明
先来一个全家福
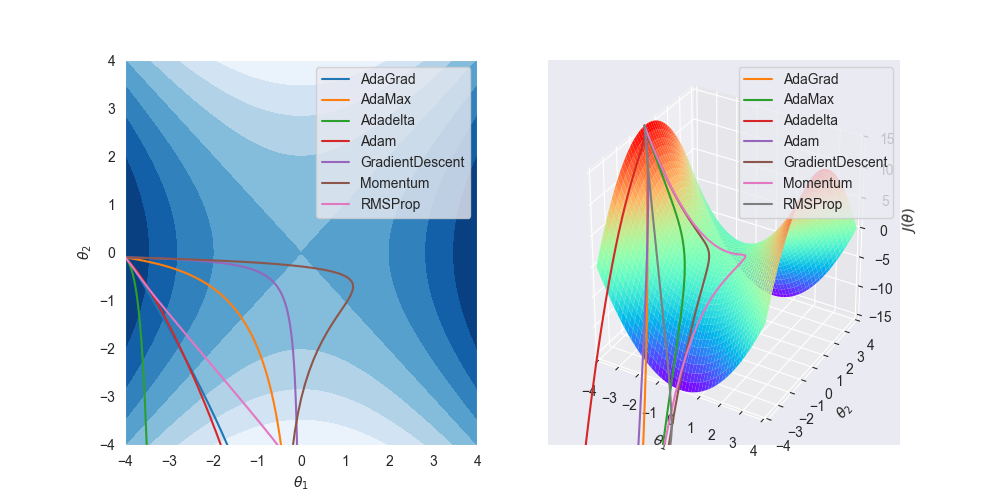
设模型的目标函数为 \[ J(\theta) = \theta_1^2 - \theta_2^2 \] 这是著名的马鞍面函数
对应的梯度为 \[ \nabla_\theta J(\theta) = (2\theta_1,-2\theta_2) \]
左图为 \(J - \theta\) 空间等高面,右图为对应的3D图,其中的曲线为各个算法的求解路线。
3. GradientDescent
3.1. 算法流程
input:学习率 \(\eta\),初始参数 \(\theta\)
repeat
- 梯度计算:$ _J() $
- 权值更新:\(\theta \leftarrow \theta - \eta \mathbf{g}\)
until 达到收敛条件
3.2. 拟合效果
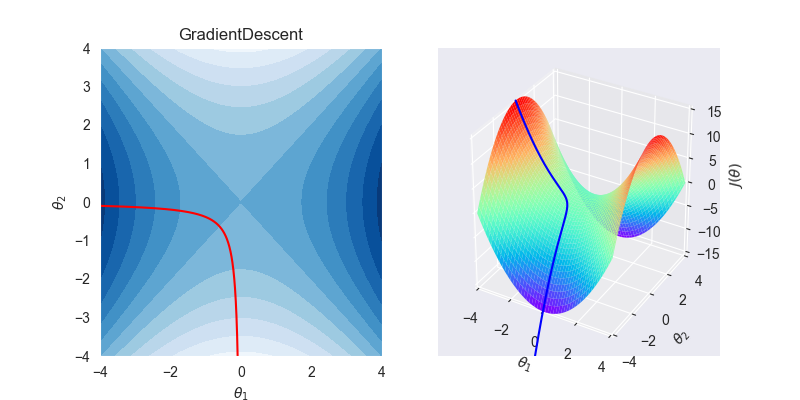
3.3. 算法特性
- 梯度下降法是求解无约束问题最常用的手段,简单稳定
- 忠于目前前进的方向,所以GD是很固执的,极其容易陷入局部最优解,从上图中也可以看出,拟合曲线先奔向局部最优解,然后才艰难地改变方向寻找另一个最优解
- 下降的步长固定,前期训练慢,后期容易震荡不收敛。
- 不适用于高维空间
- 一般图像处理任务使用梯度下降法。
GD还可以继续细分为
- 批量梯度下降(Batch gradient descent,BGD):每次权值更新使用全量训练集数据
- 小批量梯度下降(Mini Batch Gradient Descent,MBGD):每次权值更新使用部分训练集数据
- 随机梯度下降(Stochastic Gradient Descent,SGD):每次权值更新,对训练集重新打乱,逐条更新
上面分类只是取样方法上不一样,但本质上都是GD算法,不多赘述。
4. Momentum
4.1. 算法流程
input:学习率 \(\eta\),动量参数 \(a\),初始参数 \(\theta\),初始速度 \(\mathbf{v}\)
repeat
- 梯度计算:\(\mathbf{g} \leftarrow \nabla_\theta J(\theta)\)
- 速度更新:\(\mathbf{v} \leftarrow \alpha \mathbf{v}-\eta \mathbf{g}\)
- 权值更新:\(\theta \leftarrow \theta+\mathbf{v}\)
until 达到收敛条件
4.2. 拟合效果
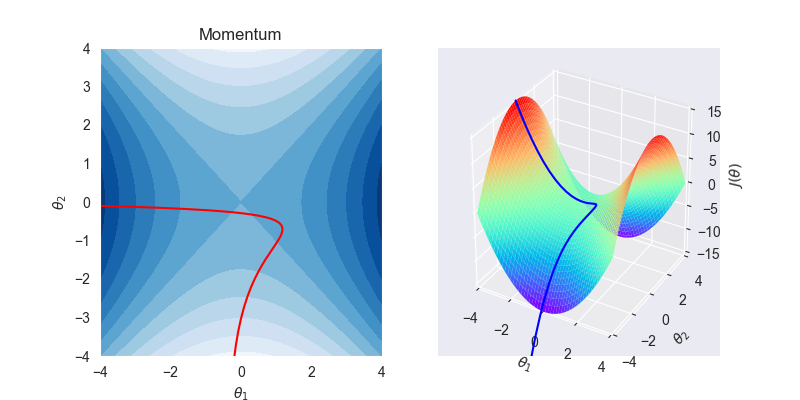
4.3. 算法特性
带动量的梯度下降法是GD的改进
类比物理上的落体运动,没有阻力时,它的动量会越来越大,但是如果遇到了阻力,速度就会变小。于是,在梯度方向改变时,momentum能够降低参数更新速度,从而减少震荡;在梯度方向相同时,momentum可以加速参数更新, 从而加速收敛。总而言之,momentum能够加速GD收敛,抑制震荡。
momentum还有一个变种算法NAG(Nesterov accelerated gradient),梯度计算中也加入动量,变为 \(\mathbf{g} \leftarrow \nabla_\theta J(\theta - \alpha \mathbf{v})\),其他计算不变,拟合速度前期比momentum快很多
5. AdaGrad
5.1. 算法流程
input:学习率 \(\eta\),初始参数 \(\theta\),小常数 \(\delta>0\),初始梯度累计变量 \(r=0\)
repeat
- 更新梯度:\(\mathbf{g} \leftarrow \nabla_\theta J(\theta)\)
- 梯度累计:\(\mathbf{r} \leftarrow \mathbf{r}+\mathbf{g} \odot \mathbf{g}\) (这是对应点相乘)
- 权值更新:$- $
until 达到收敛条件
5.2. 拟合效果
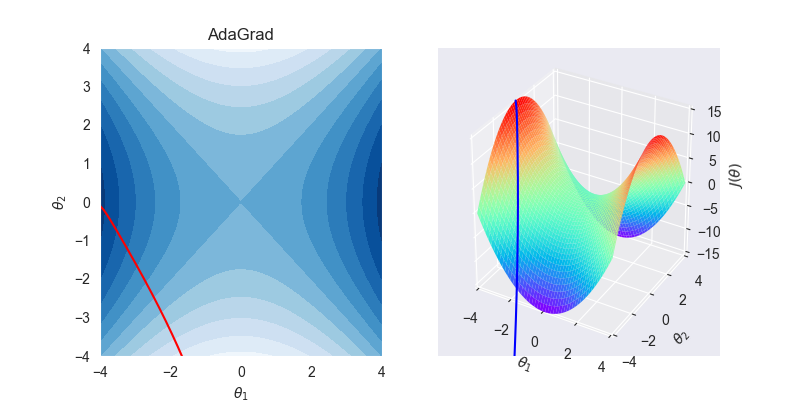
5.3. 算法特性
ada家族的优化算法都可以自适应地调节学习率,该算法通过累积梯度的变化量来自适应更新学习率。
- 在前期,梯度累计平方和比较小,也就是r相对较小,则约束项较大,这样就能够放大梯度,参数更新量变大;随着迭代次数增多,梯度累计平方和也越来越大,即r也相对较大,则约束项变小,这样能够缩小梯度,参数更新量变小。
- 根据不常用的参数进行较大幅度的学习率更新,根据常用的参数进行较小幅度的学习率更新。因此,Adagrad 适合稀疏数据(如图像识别和 NLP )的训练
- 但在中后期,分母上梯度累加的平方和会越来越大,使得参数更新量趋近于0,使得训练提前结束,无法学习
6. Adadelta
6.1. 算法流程
input:学习率 \(\eta\),小常数 \(\delta>0\),衰减速率 \(\rho > 0\) ,初始参数 \(\theta\),梯度累计变量 \(\mathbf{r}=0\)
repeat
- 梯度计算:\(\mathbf{g} \leftarrow \nabla_\theta J(\theta)\)
- 更新速度:\(\mathbf{v} \leftarrow \rho \mathbf{v} + (1-\rho)\mathbf{g} \odot \mathbf{g}\)
- 更新梯度:\(\mathbf{g} \leftarrow \sqrt{ \frac{\mathbf{r}+\delta} {\mathbf{v} + \delta}} \mathbf{g}\)
- 权值更新:\(\theta \leftarrow \theta - \eta \mathbf{g}\) (PS:按原作者的意思,这里的学习率可以省略)
- 更新梯度累计:\(\mathbf{r} \leftarrow \rho \mathbf{r} + (1-\rho)\mathbf{g} \odot \mathbf{g}\)
until 达到收敛条件
6.2. 拟合效果
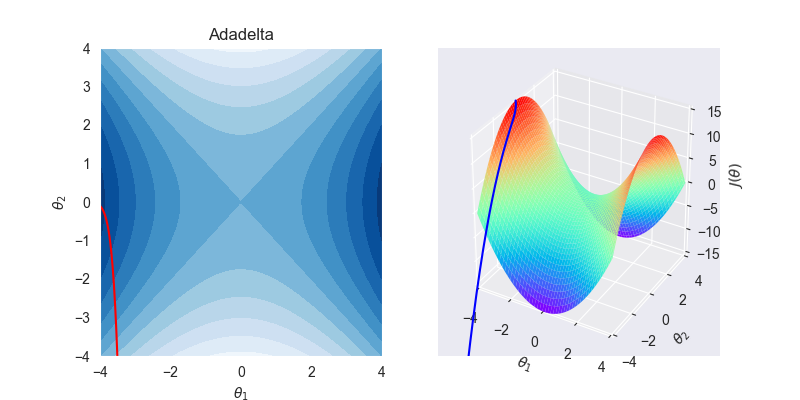
6.3. 算法特性
- AdaDelta 将累积过去平方梯度的范围限制在固定窗口 \(w\) 内,取代了经典动量算法累积所有历史梯度值的做法。
- 训练初中期,加速效果不错,很快。
- 训练后期,反复在局部最小值附近抖动。
- 训练过程不依赖学习率,真正的自适应学习。
特别地,上面的一些函数形式后面会多次用到,这里顺带一并记录,
我们把下面形式的函数称为指数加权平均 \[ E[x]_t = \beta E[x]_{t-1} + (1-\beta)x \] 该函数式的含义是:第\(t\)个数据其实是前\(t-1\)个数据加权和,其中,\(\beta\) 为前面每一个数的权重的衰减指数,即越靠前的数据对当前结果的影响较小,\(\beta\) 值一般设置较大,例如0.9
将下面形式的函数称为均方根误差 \[ RMS[x]_t = \sqrt{E[x]_t + \delta} \]
7. RMSProp
7.1. 算法流程
input:学习率 \(\eta\),小常数 \(\delta>0\),衰减速率 \(\rho > 0\) ,初始参数 \(\theta\),梯度累计变量 \(\mathbf{r}=0\)
repeat
- 更新梯度:$ _J() $
- 累计平方梯度:\(\mathbf{r} \leftarrow \rho \mathbf{r}+(1-\rho) \mathbf{g} \odot \mathbf{g}\)
- 权值更新:\(\theta \leftarrow \theta-\frac{\eta}{\sqrt{\delta+\mathbf{r}}} \odot \mathbf{g}\)
until 达到收敛条件
7.2. 拟合效果
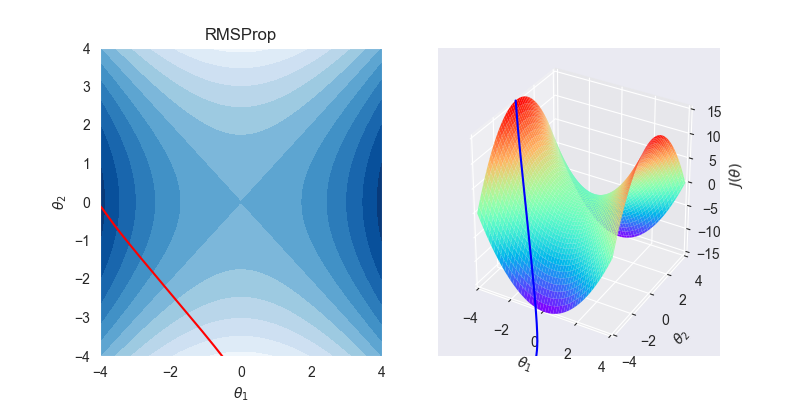
7.3. 算法特性
- RMSprop是Adagrad的一种发展,是Adadelta的变体,效果趋于二者之间
- 基于权重梯度最近量级的均值为每一个参数适应性地保留学习率。这意味着算法在非稳态和在线问题上有很有优秀的性能。
- 适合处理非平稳目标——对于RNN效果很好
8. Adam
相关论文
8.1. 算法流程
input:学习率 \(\eta\),质量衰减速率 \(\beta_1\),速度衰减速率 \(\beta_2\),小常数 \(\delta>0\),初始参数 \(\theta\),质量 \(\mathbf{m}\),速度 \(\mathbf{v}\),迭代轮数 \(t=1\)
repeat
- 梯度计算:\(\mathbf{g} \leftarrow \nabla_\theta J(\theta)\)
- 更新质量:\(\mathbf{m} \leftarrow \beta_1 \mathbf{m} + (1-\beta_1) \mathbf{g}\)
- 更新速度:\(\mathbf{v} \leftarrow \beta_2 \mathbf{v} + (1-\beta_2)\mathbf{g} \odot \mathbf{g}\)
- 质量矫正:\(\mathbf{\hat m} = \frac{\mathbf{m}}{1-\beta_1^t}\)
- 速度矫正:\(\mathbf{\hat v}=\frac{\mathbf{v}}{1-\beta_2^t}\)
- 权值更新:\(\theta \leftarrow \theta - \eta \frac{\mathbf{\hat m}}{\sqrt {\mathbf{\hat v} + \delta} }\)
until 达到收敛条件
8.2. 拟合效果
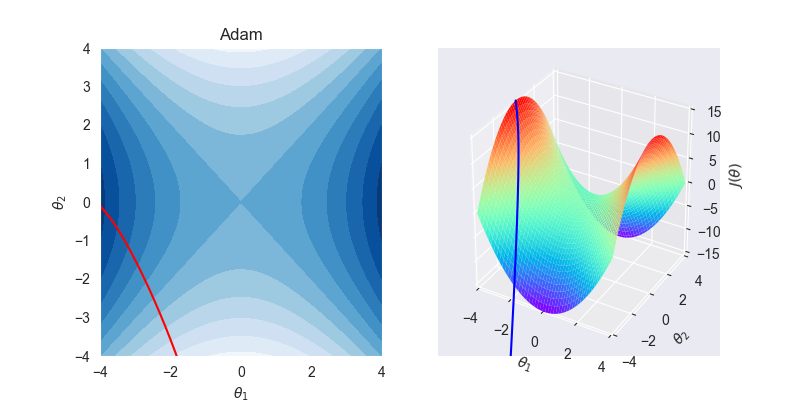
8.3. 算法特性
Adaptive + Momentum,自适应的动量下降,应该是ada家族中使用率最高的算法,万金油算法,收敛速度极快。
具有梯度偏置校正,每一次迭代学习率都有一个固定范围,使得参数比较平稳。Adam中动量直接并入了梯度一阶矩(指数加权)的估计。其次,相比于缺少修正因子导致二阶矩估计可能在训练初期具有很高偏置的RMSProp,Adam包括偏置修正,修正从原点初始化的一阶矩(动量项)和(非中心的)二阶矩估计。(我一般将其理解为质量项与速度项)
结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点
对内存需求较小
也适用于大多非凸优化问题——适用于大数据集和高维空间。
可能存在不收敛或容易错过最优解的问题。
一般NLP任务使用Adam算法。
9. AdaMax
9.1. 算法流程
input:学习率 \(\eta\),初始参数 \(\theta\),质量衰减速率 \(\beta_1\),速度衰减速率 \(\beta_2\),小常数 \(\delta>0\),初参数 \(\theta\),速度 \(\mathbf{v}\),质量 \(\mathbf{m}\),迭代轮数 \(t=1\)
repeat
- 梯度计算:\(\mathbf{g} \leftarrow \nabla_\theta J(\theta)\)
- 更新质量:\(\mathbf{m} \leftarrow \beta_1 \mathbf{m} + (1-\beta_1) \mathbf{g}\)
- 更新速度:\(\max(\beta_2\mathbf{v},|\mathbf{g}|)\)
- 质量矫正:\(\mathbf{\hat m} = \frac{\mathbf{m}}{1-\beta_1^t}\)
- 权值更新:\(\theta \leftarrow \theta - \eta \frac{\mathbf{\hat m}}{\sqrt {\mathbf{\hat v}} + \delta}\)
until 达到收敛条件
9.2. 拟合效果

9.3. 算法特性
Adam的变体,简化了速度的计算,使学习率的边界确定变得更加简单。
10. references
https://www.cnblogs.com/guoyaohua/p/8542554.html
Good luck~