transformer基础原理笔记
GPT(Generative Pre-Training)是openai提出的一种基于transformer架构的生成式的预训练模型
1. 基本定义
2018年的论文:Improving Language Understanding by Generative Pre-Training
和BERT相同的地方:
- 都是基于transformer架构
- 都是基于微调的预训练模型,但值得一提的是,GPT提出采用预训练与下游微调方式处理NLP任务这个概念的时间比BERT的要早。
与BERT不一样的地方:
- BERT基于编码器,即所谓的encoder only,GPT基于解码器,即所谓的decoder only
- GPT
的attention层是带mask结构的,所以包含了更多的时序信息,其任务的目标是预测下一个字符,即预测未来,而BERT目标是预测当前字符,即完形填空,所以GPT的任务难度比BERT要大,目前BERT的在很多任务的中成绩也比GPT好,但GPT的潜力是要比BERT高的
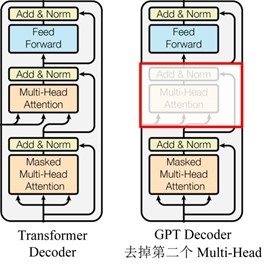
另外,GPT与原始的transformer架构不一样的是,其去掉了解码器的第二个multi-head attention,即下图所示结构
1.1. 预训练
预训练和transformer模型基本一样,没啥好说的,略过。
1.2. 微调
论文中介绍4种任务类型,如下图所示
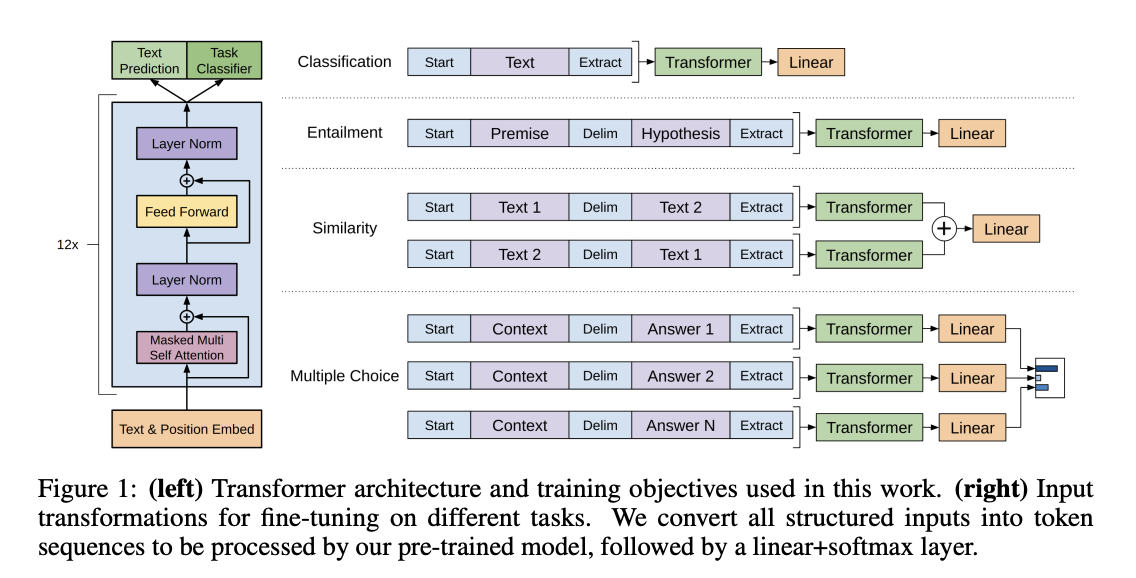
- 对于单句子分类问题,取结束符对应的隐层的输出权重,接上一个线性层即可;
- 对于句子关系判断问题,比如蕴含类任务,其实就是句子对分类任务,两个句子中间加个分隔符作为输入,取结束符对应的隐层的输出权重,接上一个线性层即可;
- 对文本相似性判断问题,也是句子对分类任务,把两个句子顺序排列及颠倒排列分别作为两次输入,这是为了告诉模型句子顺序不重要,取结束符对应的隐层的输出权重,接上一个线性层即可;
- 对于多项选择问题,还是句子对分类任务,把文章和n个答案选项分别拼接作为多次输入即可。从上图可看出,这种改造还是很方便的,不同任务只需要在输入部分施工即可,取结束符对应的隐层的输出权重,接上一个线性层即可
2. 其他相关工作
2.1. GPT2
2019年的论文:Language Models are Unsupervised Multitask Learners
代码实现:
一些工作的亮点:
- 使用了更大的训练集,模型参数更多(15亿个参数)
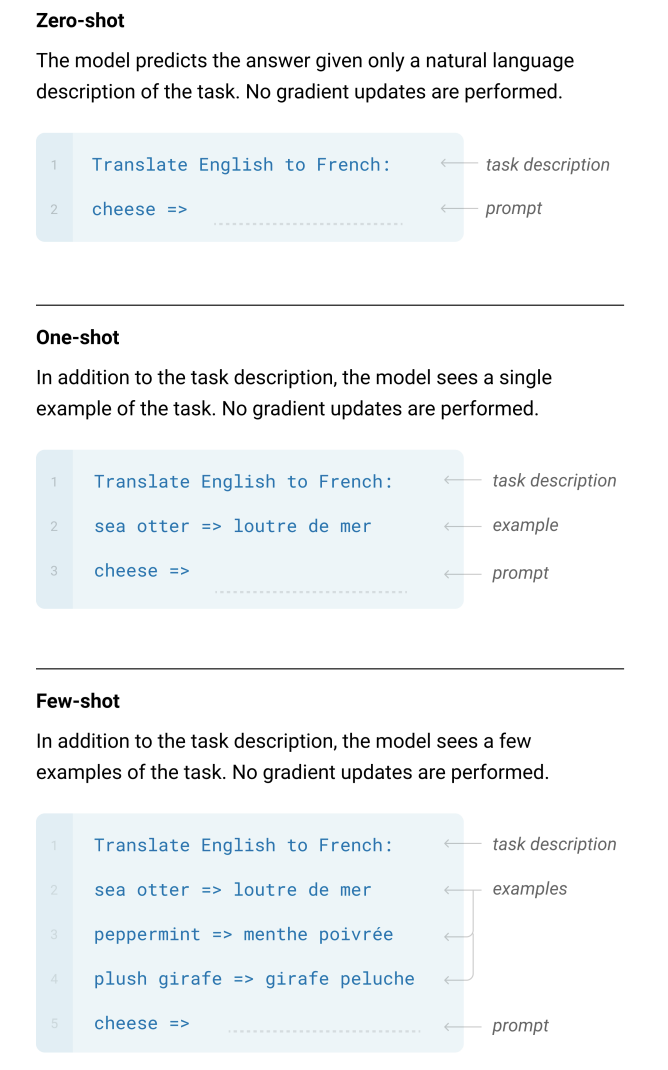
- 使用了zero-shot,即下游任务不需要提供已标注的数据,模型也不需要再训练,是一个真正的数据无关、任务无关的通用的语言模型
- 为了使其语言模型尽可能的通用,应保持下游任务的文本与预训练文本尽可能的一致,所以预训练文本也不需要经过像词干化这样的会改变原始数据的文本预处理
- 特别地,预训练的输入也不能再使用像开始结束符这些特殊的token,转而使用prompt提示文本。例如翻译任务的输入为:
(translate to french, english text, french text),其中,translate to french就是prompt提示文本
2.2. GPT3
2020年的论文:Language Models are Few-Shot Learners
一些工作的亮点:
整个框架基本还是基于GPT2,只是使用了更更更大的训练集,模型参数更更更多(1750亿个参数!)
由于需要很多的训练数据,之前的GPT2的训练集已经远远不足,所以GPT3将GPT2用来的训练的数据集作为一个高质量的正类数据集,将CommonCrawl作为一个低质量的负类数据集,简单的训练一个二分类器,在低质量的数据集中筛出一些相对高质量的数据,补充进原来的高质量数据集。同时,使用lsh算法过滤相似的训练数据
使用了few-shot,即预测的时候允许需提供少量的已标注的任务数据作为参考(当然,few-shot是包含了one-shot和zero-shot的)。这里的few-shot样本在原论文中虽然是称为一个learning的过程,但实际上还是作为预测样本进行输入,所以是不会更新网络的参数的。例如

但这种做法无法缓存每次输入的参考样本,也就是说每次预测时都需要输入一个参考样本,并不好直接用于实际应用中
3. references
https://jalammar.github.io/illustrated-gpt2/