transformer基础原理笔记
BERT(Pre-training of Deep Bidirectional Transformers for Language Understanding)是Google提出的一种基于transformer架构的预训练模型。
1. 基本定义
2019年的论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
代码实现:
BERT之前的预训练模型,像word2vec,预训练好的参数都不需要再进行更新,而且预训练好的权值一般作为embedding层。不同于以往的预训练模型,BERT是一种基于微调的预训练模型。
所以很自然的,其训练训练分为两个阶段:预训练(Pre-train)和微调(Fine-tune)。预训练就是使用一个未标记的通用数据集训练,得到基础模型;微调就是使用基础模型,通过增加一个特殊的输出层,在已标记任务数据集继续训练,得到对应的任务模型。
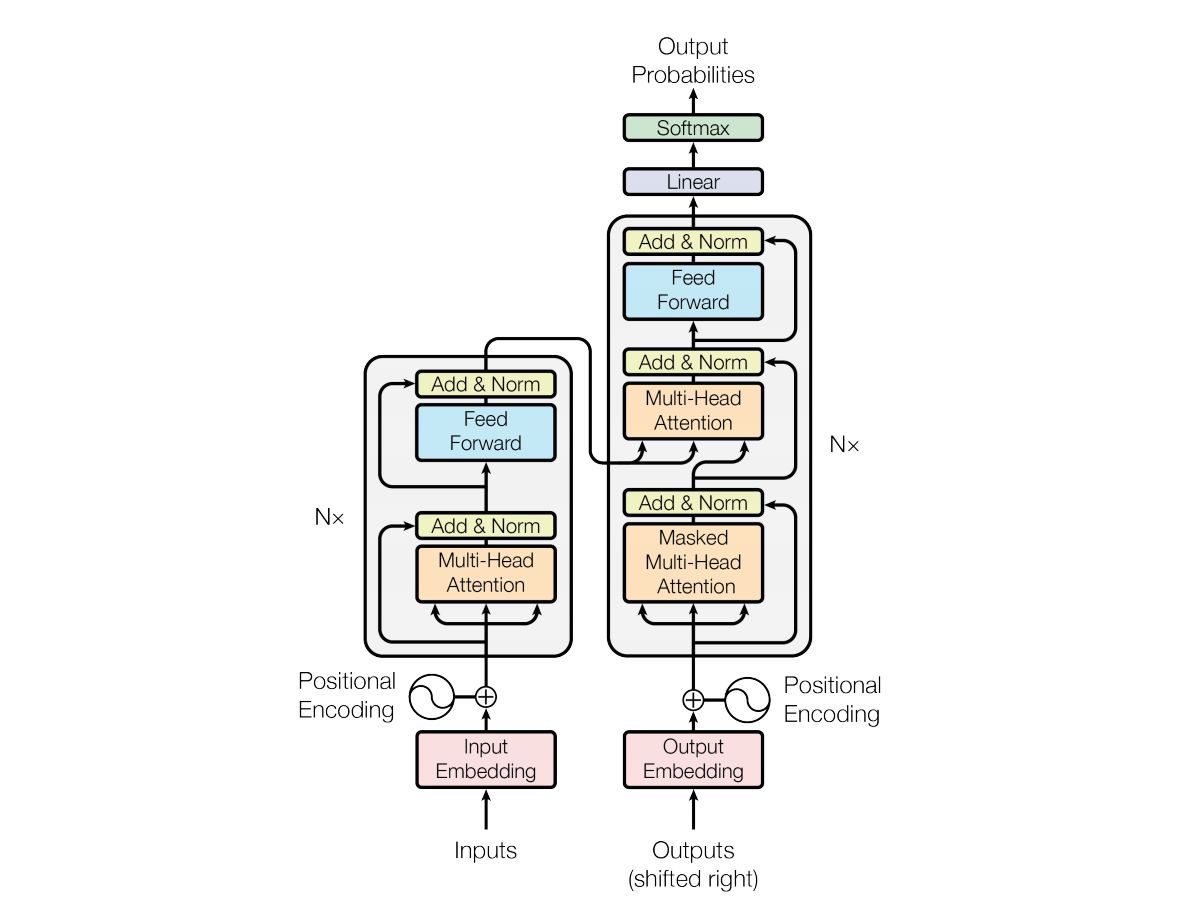
而BERT完全是基于transformer的编码器(所以其可以比RNN处理较长的序列,而且是双向的),所以其模型结构本身并没有太多创新的地方(当然也有一些改进的地方,例如将激活函数由relu改为gelu),其本身是一个trick味很浓的模型。
下面介绍BERT在不同阶段、不同任务下用到的一些trick。
1.1. 预训练
1.1.1. WordPiece
会对一些出现评率较低的单词拆分为两个出现频率较高的词,所以一定程度上可以认为是做了一个词干化处理,例如,playing -> play ##ing
这样做的好处是
- 减少了词库的大小,降低了模型训练的难度
- 在一些特殊情境下,
##后序的词可以被忽略,不输入模型进行训练
1.1.2. Masked Language Model(MLM)
由于预训练模型基本都是无监督学习,但是训练的时候需要获得一个训练的目标,和word2vec类似,BERT将一个序列中的某个元素拎出来,作为本次训练的预测目标,其本质就是让模型做完形填空。这一类型的模型又称为掩码语言模型。
具体的做法为:
将序列中每个元素随机(15%概率)地替换成
[MASK]标记符但由于在后序的微调任务中,不存在
[MASK]标记,为了让模型在预训练阶段就预留了微调阶段的情况,所以在15%替换概率下,再进行一次判断:- 80% 替换成
[MASK]标记 - 10% 替换为一个随机单词
- 10% 保持原样
例如:
my dog is hairy -> my dog is [MASK] // 80% my dog is hairy -> my dog is test // 10% my dog is hairy -> my dog is hairy // 10%- 80% 替换成
1.1.3. Next Sentence Prediction(NSP)
这是NLP的二元化句子预测任务,训练样本 A 和 B 组成,模型需要预测的是 B 是否是 A 的下一个句子。最常见的例子就是QA问答任务。
但由于BERT只保留了transformer的一部分,无法将 A 和 B 通过编码解码器分别输入,所以只能通过将 A 和 B 拼接成一个句子进行输入。
具体的做法为:
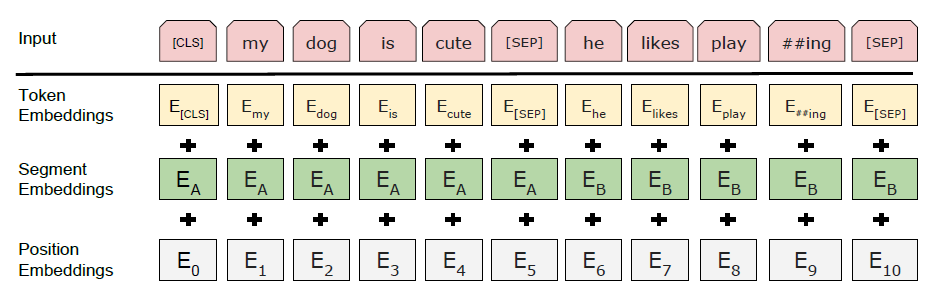
每个序列的第一个token为特殊的开始符
[CLS],A和B通过分割符[SEP]分割开,即[CLS] A [SEP] B [SEP]为了更好的区分
A和B,加入一层segment embedding,A和B用到embedding是不一样的,意味同一个单词会由于位于前后句子而得到不一样的embedding加入segment embedding后的输入层的网络结构如下:

其中,token embedding、segment embedding、position embedding都是可以被训练更新的
为了增加更多的负样本,
A和B有50% 的概率是一个自然的二元句子对,有50%的概率B是随机挑选的。例如:Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP] Label = IsNext Input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP] Label = NotNext
1.2. 微调
微调时使用的学习率应尽可能小,因为原来网络的参数学到的知识已经很丰富了。
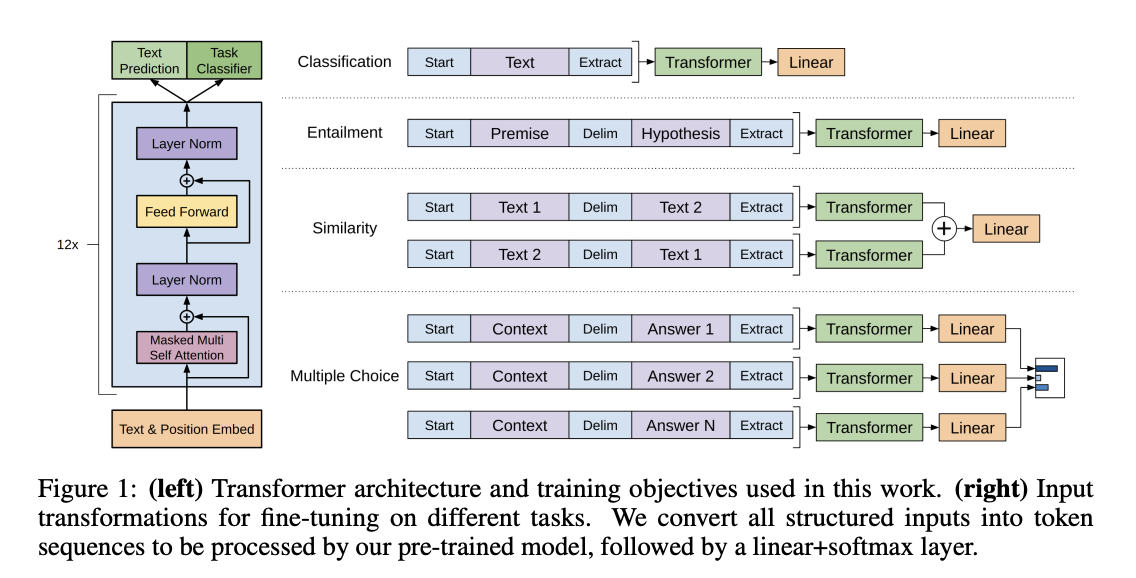
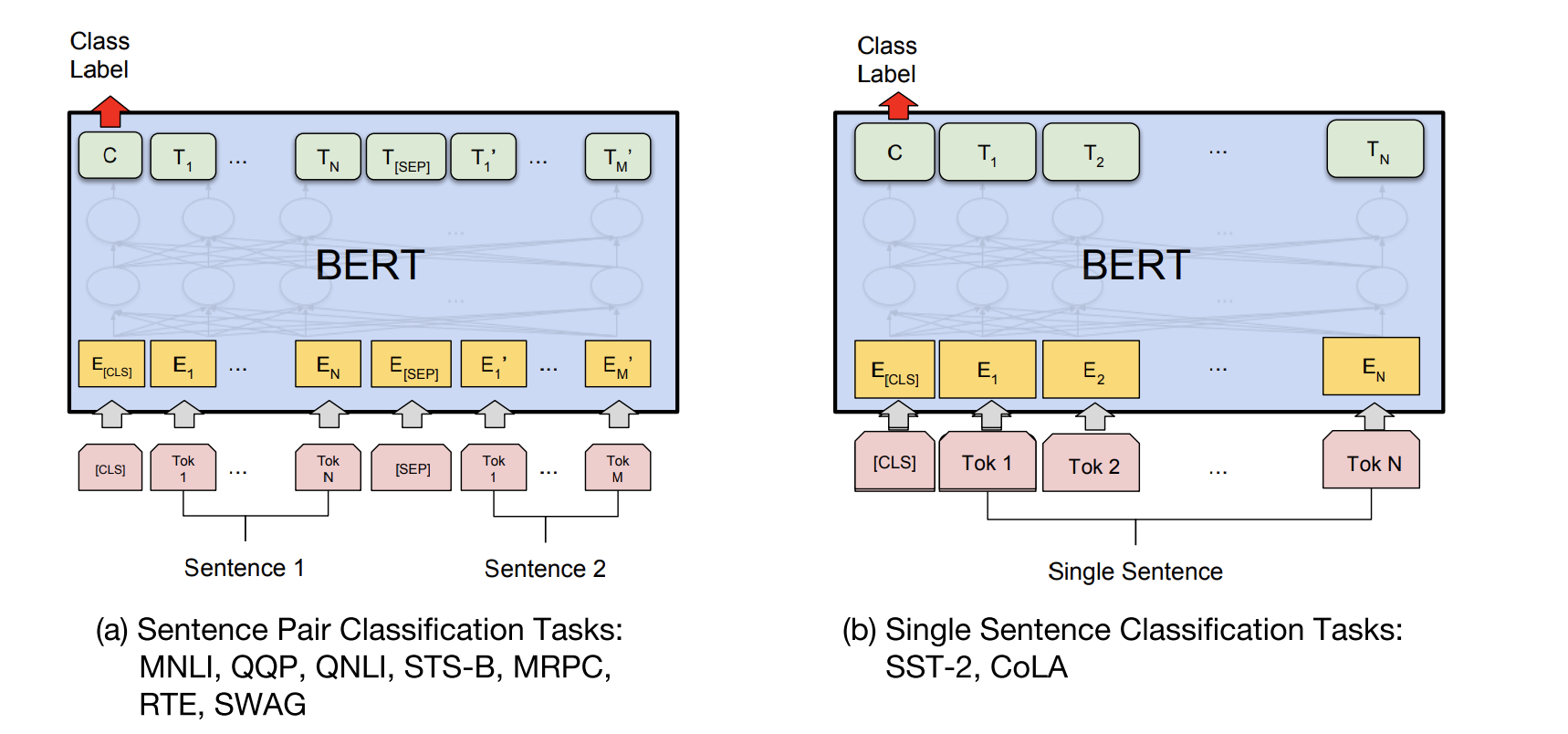
1.2.1. 句子分类任务
就是对一个文本进行分类,经典例子是情感分析
具体做法为:
- 如果是单一句子,直接使用
[CLS] A格式输入,如果是句子对,则使用[CLS] A [SEP] B格式输入 - 只取标记符
[CLS]对应的隐层输出 - 在该隐层后接入一个全连接层,训练该层的参数
网络结构如下:
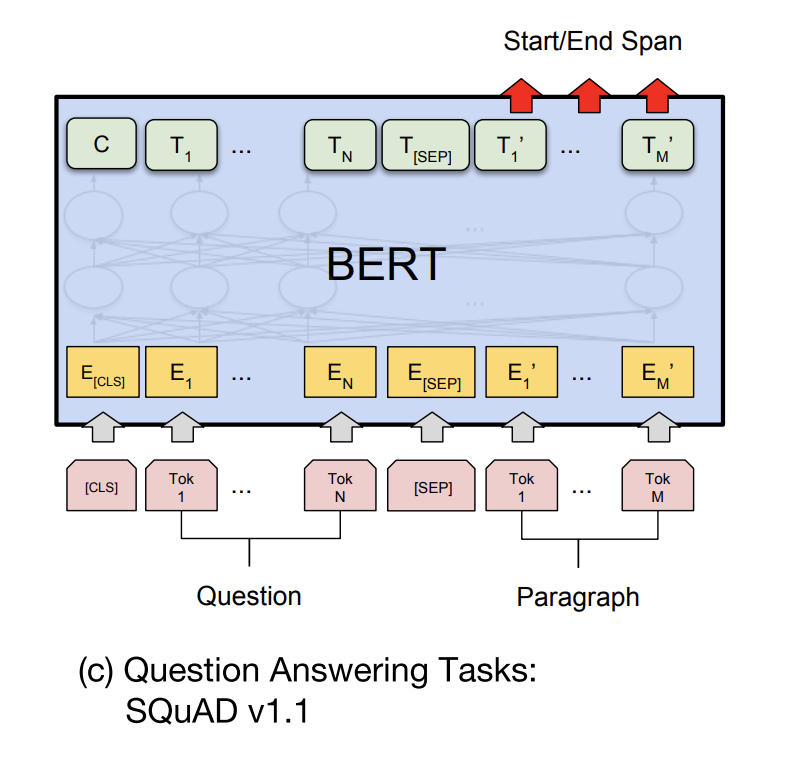
1.2.2. 问题回答任务
就是给定一个问题 A 和一段文本 B,找出 B 中能回答 A 问题的文本的位置,经典例子是阅读理解
具体做法为:
- 文本输入格式为
[CLS] A [SEP] B - 取序列
B对应的隐层输出 - 在该隐层后分别接入两个全连接层,分别预测每个token是否为开始、结束位置,损失函数为 \(\log P_s + \log P_e\)。需要注意的是,为保证结果正常,还需要增加一层约:开始位置必须在结束位置的前面
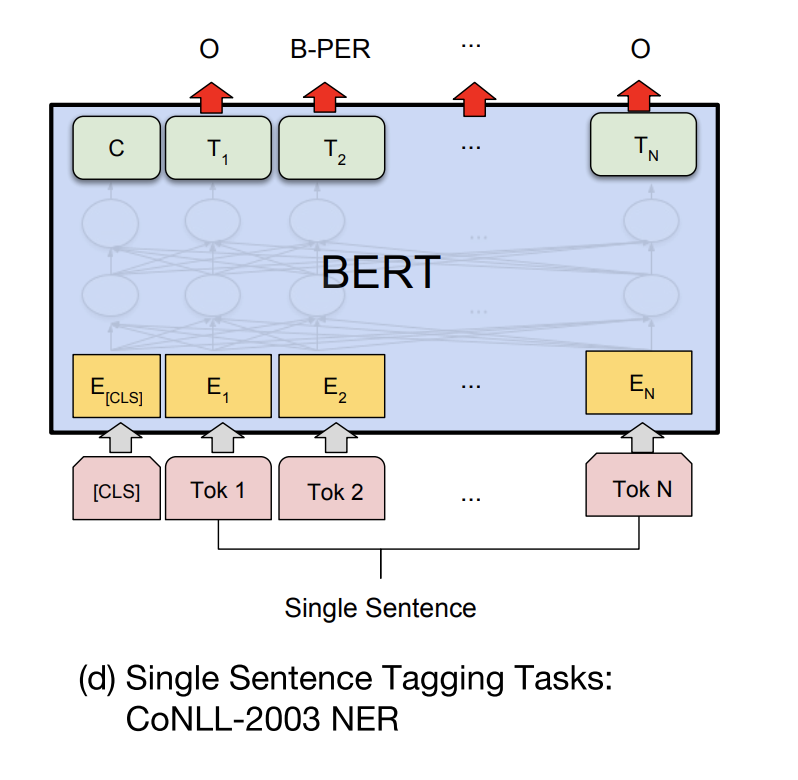
1.2.3. 标注类任务
经典例子为命名实体识别
具体做法为:
- 文本输入格式为
[CLS] A - 取除了特殊token(如
[CLS])外的token对应的隐层输出 - 隐层外接入一个全连接层,训练该层的参数。但需要注意的是,如果是多batch训练,其输出的是一个3维的张量,进入全连接层前需要reshape成一个二维的
网络结构如下: