但目前没有找到doc2vec相关的具体计算公式或者具体的实现细节,所以这篇权且当做一篇科普文。
1. 基本定义
doc2vec对word2vec的一种改进。word2vec相关的推导可以参考我的这篇笔记。
传统的word2vec是以词为单位,如果要以词向量表示不定长句子的向量时,一般有两种方案:
- 直接以句子内单词的词向量均值作为句向量
- 求语料集中个单词的tf-idf权值,然后以句子内单词的词向量加权均值作为句向量
但上面的方法都缺乏较强的数学解释(例如忽略上下文信息或者忽略句法等),只能作为一种经验的做法。
也有直接以句子为单位,直接训练一个向量用来表示每一个句子,doc2vec就是其中之一。
doc2vec有两种模式框架:PV-DM(Distributed Memory Model of Paragraph Vectors,段落向量的分布式记忆)、PV-DBOW(Distributed Bag of Words version of Paragraph Vector,段落向量的分布式词袋)
原作者表示,PV-DM在多数任务上的效果会较好,建议使用两者的结合体。
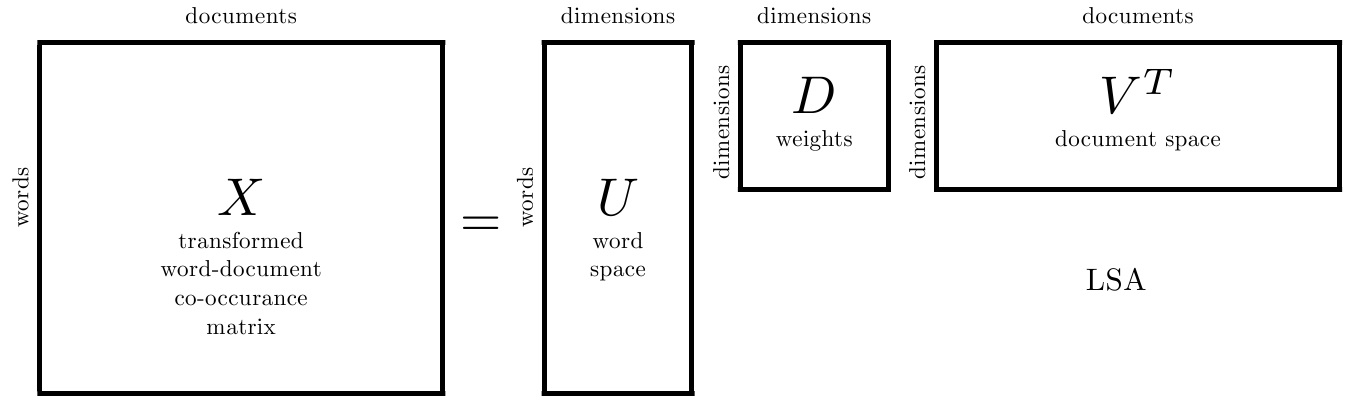
2. PV-DM
首先给出模型框架图:
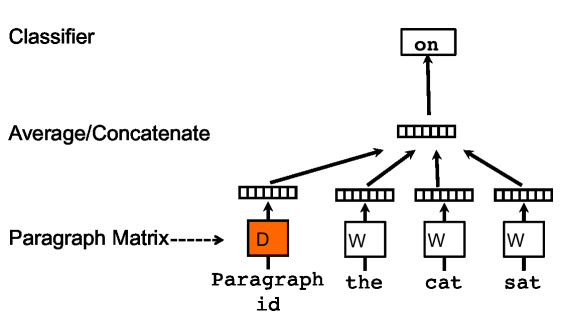
该算法思想很简单,在word2vec的CBOW模型中,输入层是上下文的词向量的均值,到doc2vec中,输入层中额外插入一个向量作为当前句子的向量,该向量与每个词向量拼接成一个新向量后做平均作为输入(或者直接将其与其他词向量一起做均值作为输入,这要求句向量的维度和词向量的维度保持一致)。
该向量在同一句子中是共享的,这就意味着,假设语料集中有 \(N\) 个不同的句子,每个句向量的维度为 \(p\),则句向量矩阵的大小应当为 \(N \times p\)
该向量可以看做是当前预测单词的记忆向量,因为每次训练时滑动窗口取样作为输入,所以单次训练是没有当前句子窗口外单词的信息,由于句子内的句向量是共享的,所以每次训练迭代后,句向量都把当前窗口下的单词记忆下来,带到其他窗口中进行训练。若干次训练后,该局向量即为当前句的主题向量。
3. PV-DBOW
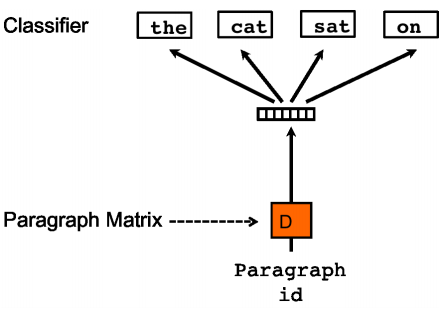
其输入为当前句的句向量,输出为当前句中单词的预测,即按单词对每个句子进行分类,由于输出无论是采用均值还是耦合拼接,都不带有顺序信息,这就意味着其忽略了上下文信息。
4. 结果预测
doc2vec算法设计的最妙的地方是其结果预测,因为一般神经网络都是由输入预测输出,但该算法是由输入预测输入。
该算法的预测,也是通过梯度下降进行求取的。更加具体的,在预测阶段,随机初始化一个句向量,按照训练阶段的做法,对句向量进行更新,最终收敛即得到输入句的句向量,但唯一不一样的是,该过程需要冻结隐藏层和输出层的参数,所以最终迭代消耗的时间较小。