实现代码传送门
1. 概览
看了一圈,目前已有的网页正文提取的思路有下面几种
- 基于标签类别分析,根据标签用途的抽取,例如正文的标签多为
<p>标签,所以这种方法实质上还是正则抽取,需要人工总结所有可能文本的标签,然后根据总结的标签抽取出正文部分。 - 基于统计分析,通过统计网页的文本密度,根据文本成块的规律,抽取出正文部分。
- 基于计算机视觉分析,根据网页视觉特征,将网页直接划分为正文和非正文部分,但需要大量人工标注的训练集支持,而且训练需要消耗的资源也较大。
- 基于机器学习分析,一种方法是将其转化为无监督学习问题,将网页根据标签和文本进行编码转化,然后使用聚类的方法抽取出正文的部分;另一种是将其转化为分类问题,人工标注标签和文本部分,然后训练分类器进行分类。
后两种思路据说准确率较高,但运行效率较低,有点牛刀小用的感觉;而第一种思路并非真正的自动抽取,直接pass掉;所以本文主要研究第二种分析思路,其准确率和运行效率都尚可,也是目前用得比较多的方法。
2. 网页组成成分
网页的正文抽取,可以分为长文本类和短文本类网页,一般的正文抽取任务大多为长文本的抽取。长文本类网页最典型的就是新闻类网站。
下面随机挑选的一篇新闻,页面组成成分可以划分以下几个部分

3. 行块分析
首先需要进行预处理,去除网页html中的css、js、代码段、备注和标签部分,统计每一行的字数。特别地,这里字数统计是以中文字符作为计量单位,所以按照经验,需要将每2~4个非中文字符转换为一个中文字符。
上面新闻预处理后字数统计如下
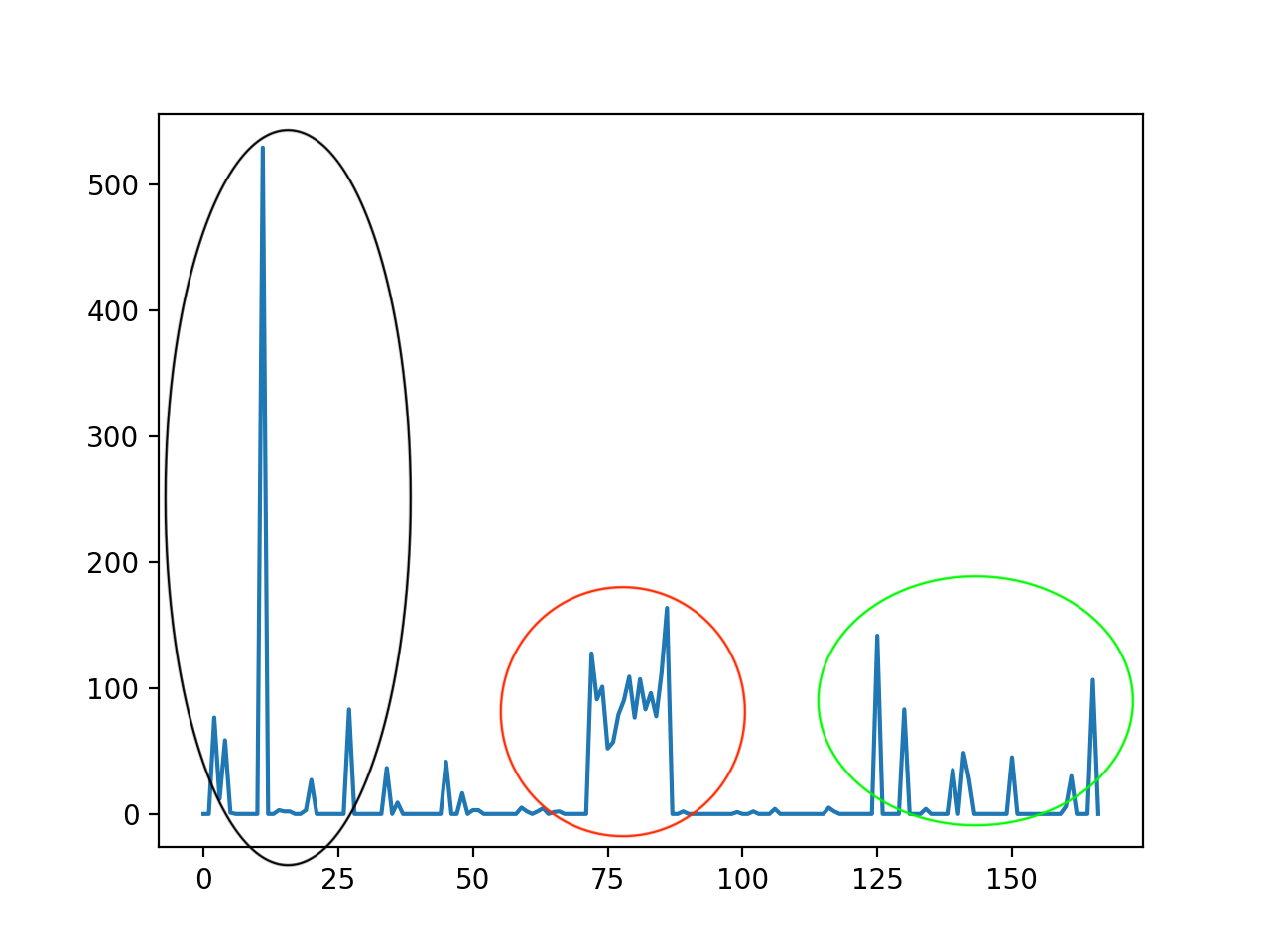
上图中,每一个凸起(后面我们称这个为每一个文本段的能量值)都代表一个行块,当能量值高于一定阈值,那这一部分就属于正文内容的一部分。一般是直接判断曲线的骤起点和骤降点来设置阈值,但如果直接判断,会产生一些问题:
首先,上图中可以划分为3个行块密度较大的区域,直觉告诉我们,这个3个区域应该都分别是一个正文部分(尽管最后的结果表明只有红色部分是正文部分),但由于我们只根据骤起点和骤降点判断,由于曲线起伏较大,存在多个波峰和波谷,会把原本是一个整体的正文部分割裂成多个小段,就会导致中间一些能量较小的段落被忽略掉(如上图中绿色圈的中间部分就很大概率被忽略掉)。
其次,阈值很难各处一个适当值。给的过低,许多杂质部分会被当成正文提取出来;给得过高,正文部分容易被忽略掉,更有甚者,有一些“一枝独秀”的杂质部分的能量值会远远高于正文部分(如图中红色圈),这种情况下,不能保证在提取正文的同事去除掉杂质部分。而且不同网页的段落的能量分布也不尽相同,我们很难直接给出一个适当的阈值。
所以,我们需要对曲线进行平滑处理,来减轻上面的问题。
我们设置一个长度为 \(n\) 的平滑窗口,每一行的字数为前后共 \(n\) 行字数之和的均值,即将文章中势能高的部分均摊势能低的部分(有点像word2vec中的词袋模型),平滑后的情况如下
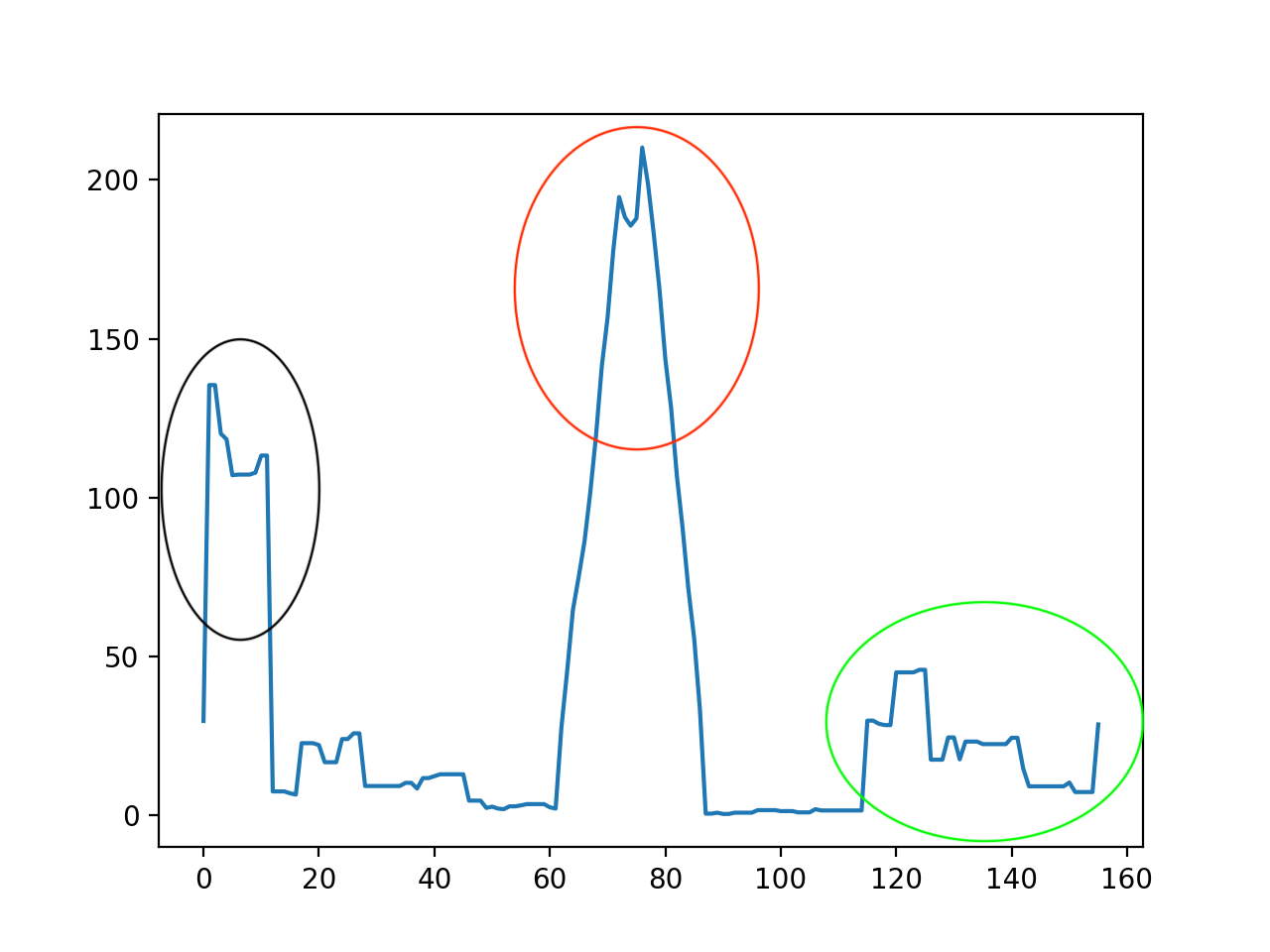
但从上面可以看出,原本能量值较低红色区域变成能量值最高的区域,这样我们就可以很容易地抽取出该网页中的文本部分了。下面就是阈值设置的问题
4. 阈值设置
我们不能站着上帝视角,根据上图想当然地把阈值设置为150,这个阈值其实是比较高的,会过滤掉许多正确的文本。不同网页的能量分布不一样,这个网页的新闻其实算是比较长的文本,有些比较短的新闻会只有几句话,总字数加起来可能也没有150个,还要再做个均值,更加没有150,这肯定是会被误过滤掉的。
我们通过设置文本开始点和终止点这两个阈值,来实现我们想要的功能。
首先,我们需要确定我们抽取的原则。
如果是“宁可错杀一千,不可放过一个”的原则,即不管抽出来的是不是杂质部分,尽可能多地抽取出文本内容,至于里面的杂质内容后面再想办法去掉。按照这个原则,我们只需要把上图绿色部分过滤掉即可,或者直接抽取出来也是没有问题的。所以,起始点和终止点的设置都应尽可能地宽容(即阈值设置得尽可能地低)。
如果是”宁缺毋滥“的原则,即非常谨慎得判断正文部分,但一旦确定是正文部分,我们就不会轻易地将其放走,这样可以减少后面除杂的工作量。所以,起始点的设置尽可能严格,而终止点的设置应尽可能地宽容。
5. 抽取情况
上面新闻网页采取”宁缺毋滥“的原则的抽取结果如下:
综合消息:盛赞发展成就期待深化合作——多个国际组织和国家的政要祝贺新中国成立71周年走路跑步“攒信用”健康管理成时尚青稞酒酥油茶更加香甜——青藏铁路铺就致富路兵撒万里淬炼三栖尖刀——海军陆战队打造多维一体新型作战力量记事专访:“我们需要向中国‘取经’”——访西班牙旅游推广协会秘书长阿韦利亚新华网评:有一种乡村振兴,叫留住乡愁专访:中国减排承诺令世界感到鼓舞——访东盟副秘书长康富阿富汗发生汽车炸弹袭击省长车队事件致36人死伤中国市场为阿根廷精酿啤酒商带来希望吉林松原重大交通事故后续:轻型普通货车上16人全部死亡多为去收玉米的农民综合消息:盛赞发展成就期待深化合作——多个国际组织和国家的政要祝贺新中国成立71周年走路跑步“攒信用”健康管理成时尚青稞酒酥油茶更加香甜——青藏铁路铺就致富路兵撒万里淬炼三栖尖刀——海军陆战队打造多维一体新型作战力量记事专访:“我们需要向中国‘取经’”——访西班牙旅游推广协会秘书长阿韦利亚新华网评:有一种乡村振兴,叫留住乡愁专访:中国减排承诺令世界感到鼓舞——访东盟副秘书长康富阿富汗发生汽车炸弹袭击省长车队事件致36人死伤中国市场为阿根廷精酿啤酒商带来希望吉林松原重大交通事故后续:轻型普通货车上16人全部死亡多为去收玉米的农民
客户端
搜索
频道
------------
新华社北京10月5日电综合新华社驻外记者报道:多个国际组织和国家的政要日前出席中国驻外使领馆线上或线下国庆招待会时致辞,或通过发表公报等方式,对新中国成立71周年表示祝贺,盛赞中国经济社会发展成就及在国际事务中发挥的建设性作用,并强调将同中国进一步加强合作。
世界卫生组织办公厅主任施瓦特兰德代表世卫组织总干事谭德塞致辞说,世卫组织对中国在各领域、特别是卫生保健领域所取得的成就印象深刻,新冠疫情期间,中国援助让那些最贫穷的国家“真正受益”。
...
马尔代夫外长沙希德在致辞中代表总统萨利赫向中国政府和人民致以诚挚祝贺和良好祝愿。他表示,新中国成立71年来,中国政府和人民取得了举世瞩目的发展成就。今年以来,中国取得抗击新冠肺炎疫情重大战略成果,并为世卫组织和世界各地抗击疫情提供了有力支持。(参与记者:聂晓阳、陈俊侠、马意翀、苏小坡、徐烨、王瑛、倪瑞捷、唐璐、郝亚琳、张永兴)
图集第二段是新闻正文内容,抽取出来没有什么问题,重点在于第一段为什么也被抽取出来。
第一段的内容是网页红色虚线的滚动条部分,这一行的能量值异常地高,以至于将其量能值均摊以后仍然超过阈值,这也是该算法的劣势所在,对于这种情况,该算法往往也无能为力。
6. 缺点
这其实也暴露了这一算法对于短文本网页抽取是无力的:如果想要抽取所有的短文本,势必会抽取出很多的杂质。
论坛类网站是最典型的短文本类型网站。
如下图为百度贴吧中一个帖子的平滑前后的每一行的字数情况

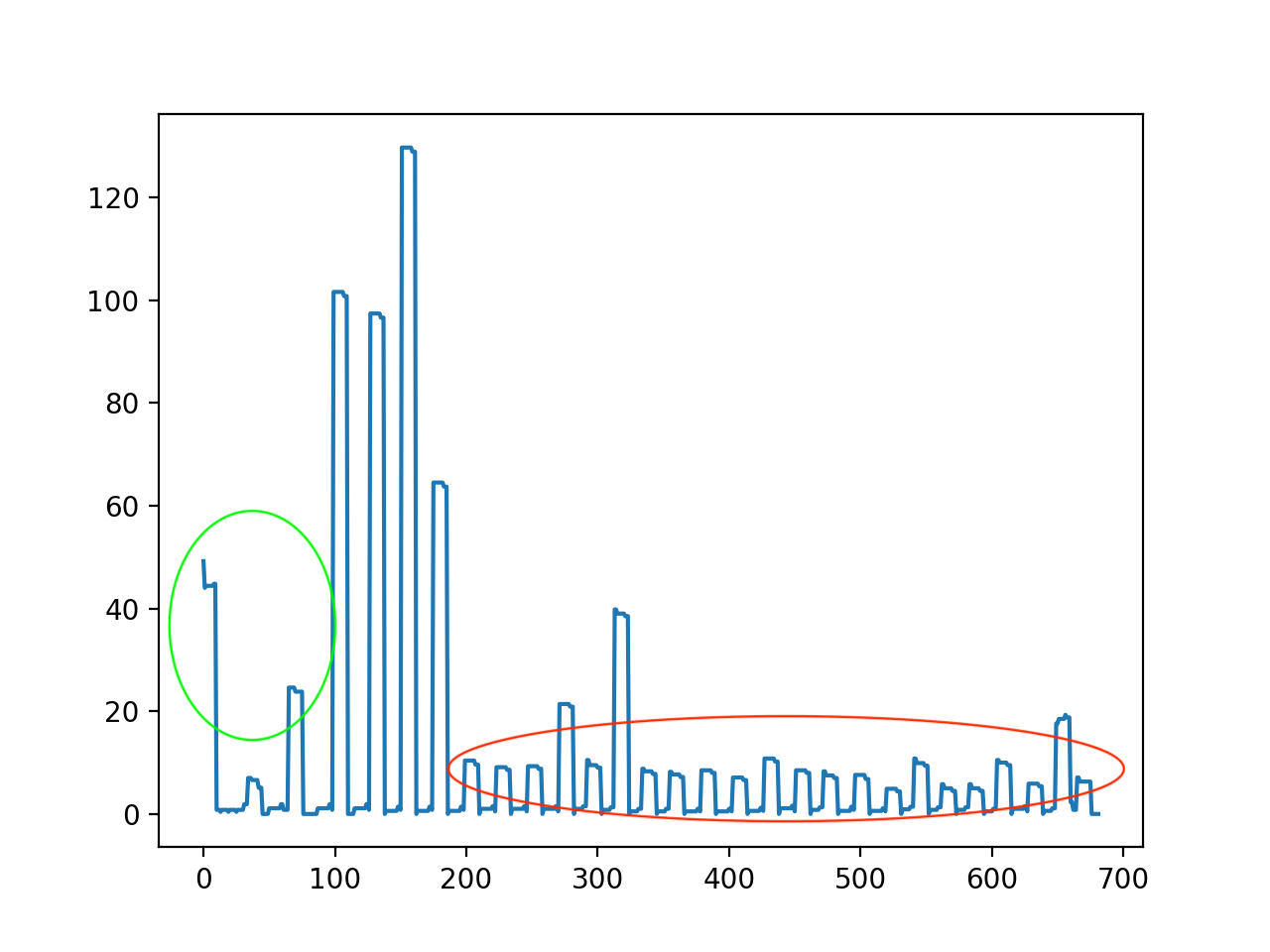
可以看到平滑后,红色区域是正文部分,绿色区域是杂质部分,这种情况下,该算法就不能再去除杂质的同时抽取出正文。
7. 平滑窗口设置
最后,说下平滑窗口这个参数,这个参数一般情况下是不用设置的,但对于一些段落比较多,而且段落间分割较明显网页,抽取的出来的正文会被分为许多段,如果不想完整的正文被割裂成多个段落,可以设置一个较大的窗口参数,将段落间的差异抹去。
其中,段落较多的网页最经典的就是百度百科的词条网页了。下面是百度百科关于爬虫的词条页面的情况
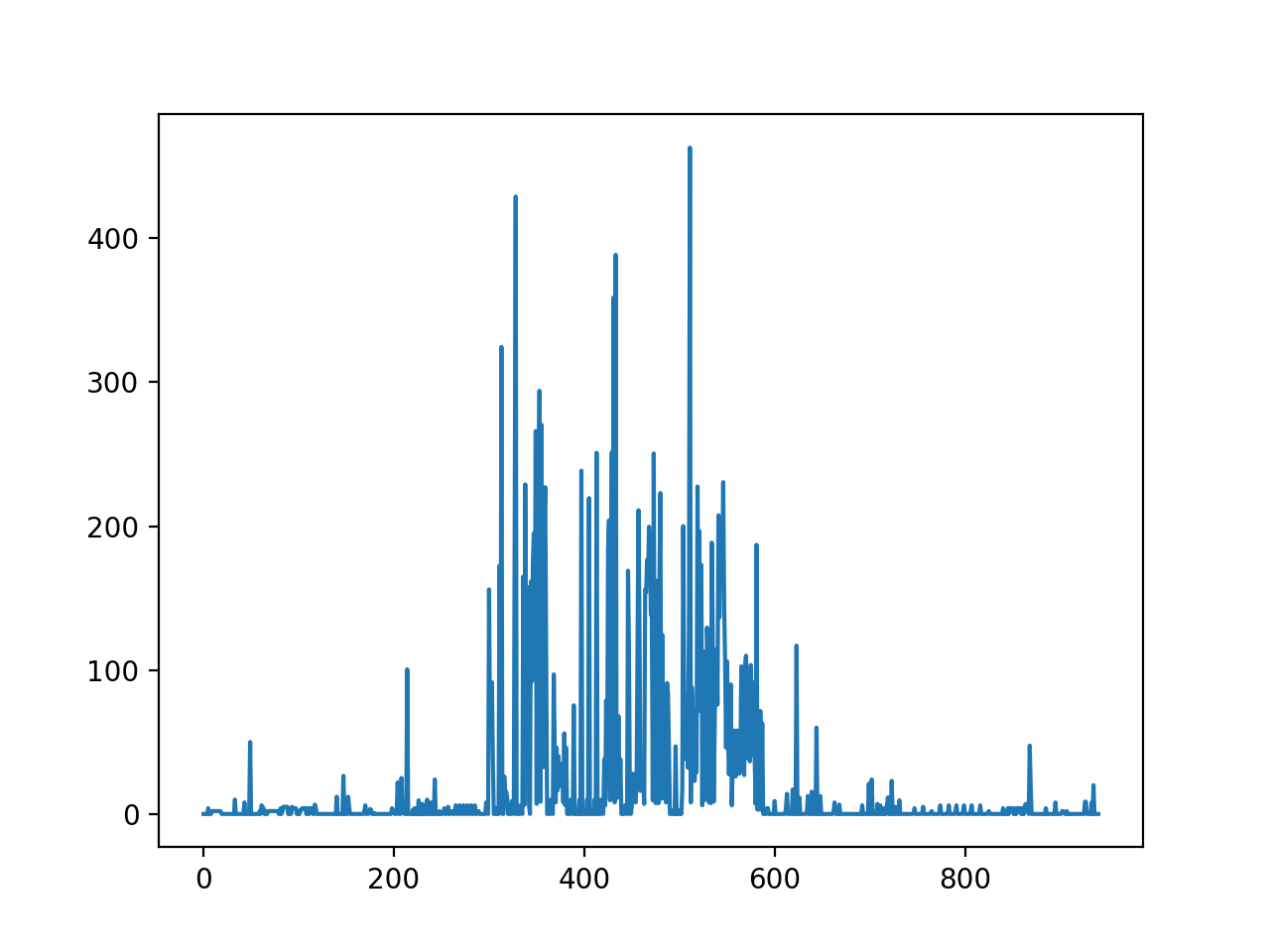
窗口为5时的平滑情况
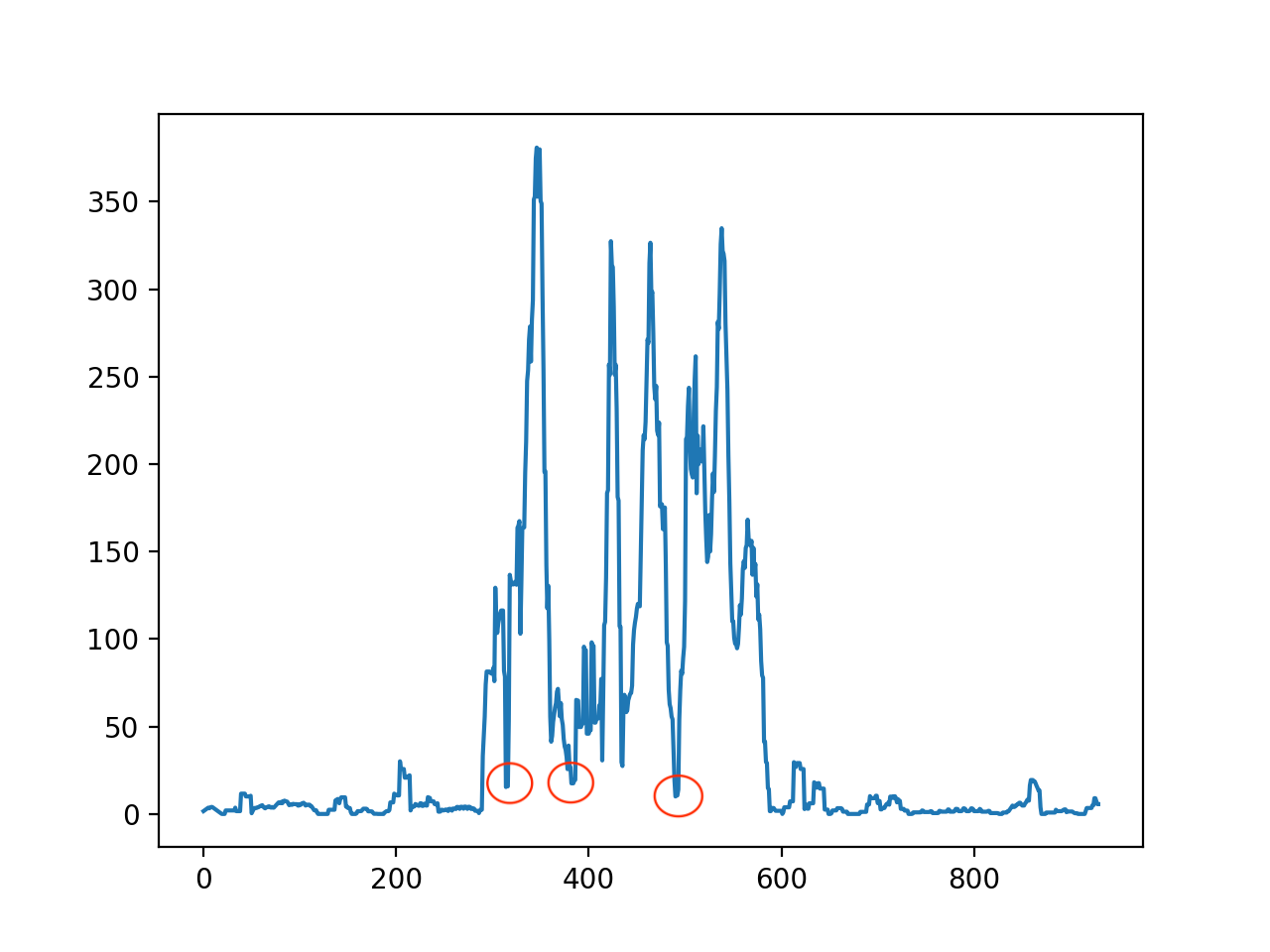
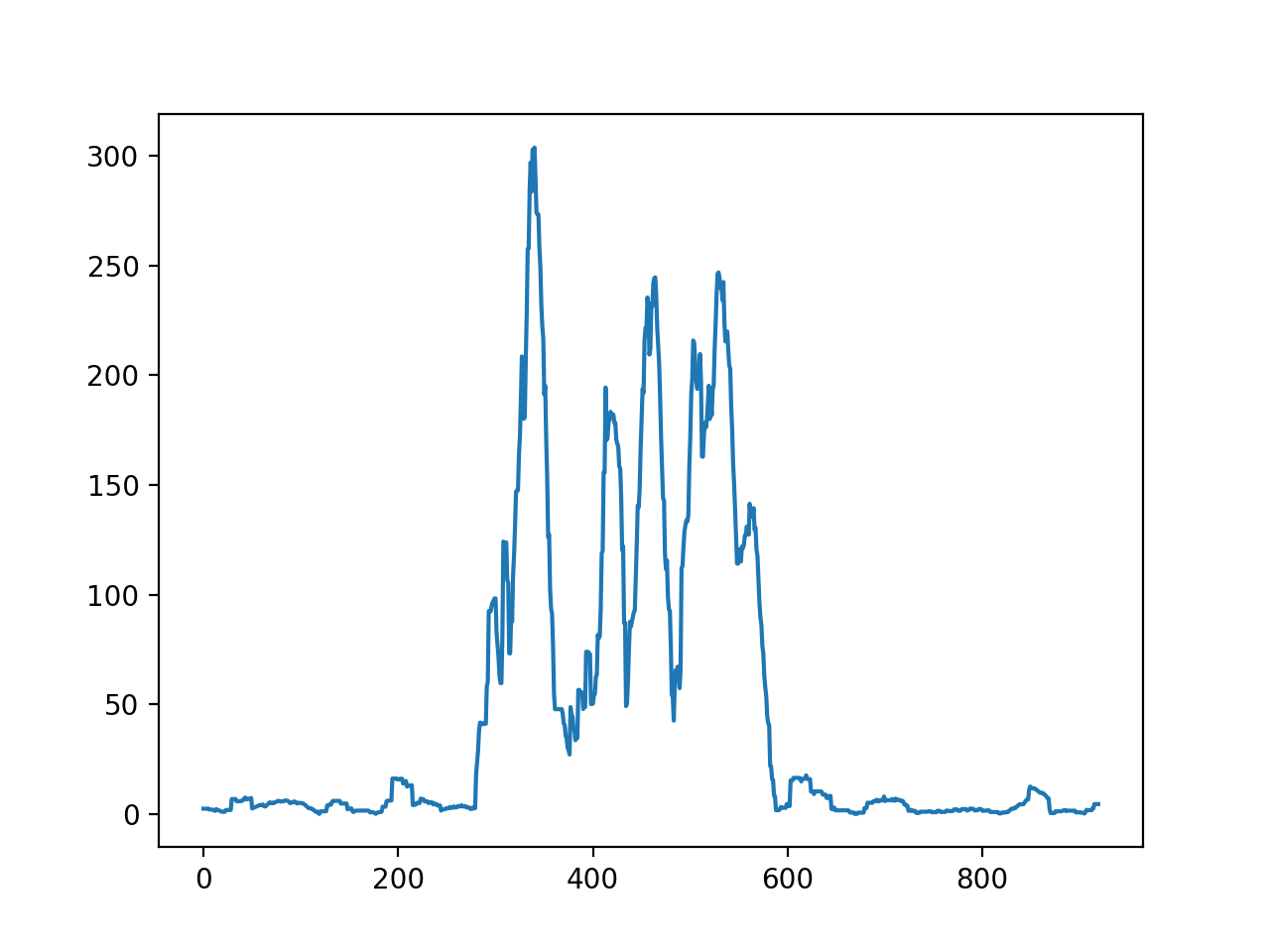
上图中可以看出,正文会在红色部分被分割成两部分,如果将窗口增大到10,那么这个问题就会减轻,如下图所示
8. 下一步工作
增加平滑窗口自适应调节功能以及尝试使用斜率作为起始点和终止的阈值。
最后有时间的话把机器学习分析的方法这个坑给补上。
Have a nice day!
9. references
https://www.cnblogs.com/jasondan/p/3497757.html
https://www.jianshu.com/p/d270cd7b517c
https://wenku.baidu.com/view/2b5c9793daef5ef7ba0d3cb5.html#
https://blog.csdn.net/qq_34202873/article/details/78452449
https://www.yuanrenxue.com/crawler/news-crawler-content-extract.html
https://blog.csdn.net/LU_ZHAO/article/details/104859697