1. 基本定义
1.1. 多线程 vs 多进程
- 多线程解决的是多个任务在一个CPU下并发运行的问题,可以直接共享变量
- 多进程解决的是多个任务在多个CPU下并行运行的问题,无法直接共享变量,只能通过特殊手段通信,共享变量。
1.2. python 的多线程问题
采用cpython作为底层解析器的python程序会存在一个叫做全局解释器锁(Global Interpreter Lock,GIL)的机制,具体的原理如下图
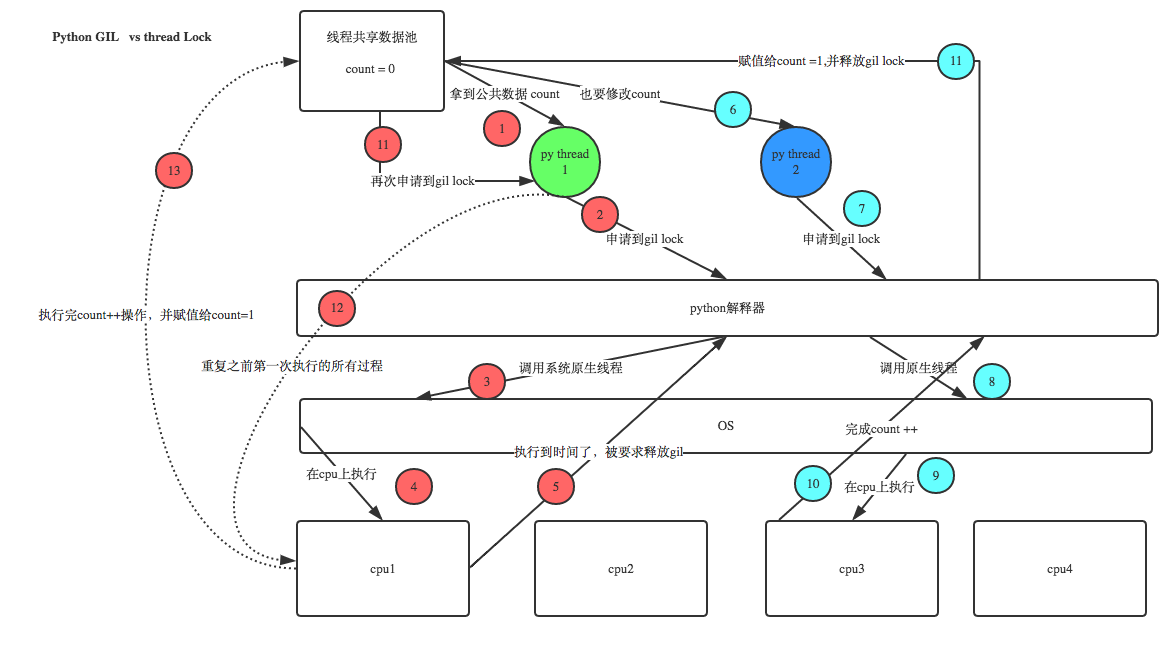
简单来说就是当cpython执行一个线程时候,会给当前的线程上锁,阻止其他线程执行,防止其他线程占用cpu资源。当执行多线程任务的时候,cpython会轮流执行python线程,使得各线程看起来像是在并发运行。
由于GIL的存在,加上python多以cpython作为底层解析器,所以python的多线程实际上是伪多线程
所以对于非阻塞类任务(典型的非阻塞型任务是各种运算类任务,典型的阻塞型任务是爬虫类等IO任务),python的多线程并不会提高效率,甚至由于任务调度,还会降低效率。
2. threading
基础多线程package
python3还自带另一个多线程package
_thread,threading是对_thread的进一步封装,所以一般都用threading代替_thread
2.1. 创建
2.1.1. 传参式
import threading
import random
import time
def worker(n):
for i in range(3):
print(f'The worker is {n}, the range is {i}')
time.sleep(random.random())
return n
threads = []
for n in range(3):
threads.append(threading.Thread(target=worker, args=(n, ))) # 不能使用 `(n)`,因为 `(n)` 不表示一个可迭代对象,但可以使用 `[n]`2.1.2. 继承式
class myThread(threading.Thread):
def __init__(self, n):
super(myThread, self).__init__()
self.n = n
def run(self):
for i in range(3):
print(f'The worker is {self.n}, the range is {i}')
time.sleep(random.random())
return self.n
threads = []
for n in range(3):
threads.append(myThread(n))2.2. 启动
print('Start threading')
for t in threads:
t.start()
print('End threading')
"""
Start threading
The worker is 0, the range is 0
The worker is 1, the range is 0
The worker is 2, the range is 0End threading
The worker is 1, the range is 1
The worker is 0, the range is 1
The worker is 2, the range is 1
The worker is 0, the range is 2
The worker is 1, the range is 2
The worker is 2, the range is 2
"""父线程结束时,会等待所有子线程结束后,才退出
2.3. 守护进程
守护进程,即后台进程,将子进程放在后台运行。当父线程结束时,不再等待子线程,直接退出,未结束的子线程会被杀死
print('Start threading')
for t in threads:
t.setDaemon(True) # 一定要放在start前面
t.start()
print('End threading')
"""
Start threading
The worker is 0, the range is 0
The worker is 1, the range is 0
The worker is 2, the range is 0End threading
"""2.4. 获取返回值
传参式的创建方法没有获取返回值的方法,所以只能使用继承式的创建方法,自定义一个返回的函数
class myThread(threading.Thread):
def __init__(self, n):
super(myThread, self).__init__()
self.n = n
def run(self):
for i in range(3):
print(f'The worker is {self.n}, the range is {i}')
time.sleep(random.random())
def get_result(self):
return self.n2.5. 阻塞
print('Start threading')
for t in threads:
t.daemon = True
t.start()
for t in threads:
t.join()
print('End threading')
"""
Start threading
The worker is 0, the range is 0
The worker is 1, the range is 0
The worker is 2, the range is 0
The worker is 1, the range is 1
The worker is 0, the range is 1
The worker is 2, the range is 1
The worker is 0, the range is 2
The worker is 2, the range is 2
The worker is 1, the range is 2
End threading
"""join阻塞了父线程,所以即使子线程加入守护进程,但仍然要等待当前子线程运行结束后,才能继续往下执行语句
对于join的阻塞作用,可以用下面例子加深理解
print('Start threading') for t in threads: t.start() threads[0].join() print(0) threads[1].join() print(1) threads[2].join() print(2) print('End threading') """ Start threading The worker is 0, the range is 0 The worker is 1, the range is 0 The worker is 2, the range is 0 The worker is 0, the range is 1 The worker is 2, the range is 1 The worker is 0, the range is 2 0 The worker is 1, the range is 1 The worker is 2, the range is 2 The worker is 1, the range is 2 1 2 End threading """上面例子中,
- 走到
threads[0].join()时,0号线程未结束,所以父线程阻塞;等待其结束后,打印出0,然后继续往下走;- 走到
threads[1].join()时,1号线程未结束,所以父线程阻塞;等待其结束后,打印出1,然后继续往下走;- 走到
threads[2].join()时,2号线程已结束,所以直接往下走,打印出2,然后继续往下走- ......
上面例子也反映了一个需要注意的地方,一定要等所有子线程都start后,才加入join方法,否则就会下面例子一样,多线程退化成普通的单线程
print('Start threading') for t in threads: t.start() t.join() print('End threading') """ Start threading The worker is 0, the range is 0 The worker is 0, the range is 1 The worker is 0, the range is 2 The worker is 1, the range is 0 The worker is 1, the range is 1 The worker is 1, the range is 2 The worker is 2, the range is 0 The worker is 2, the range is 1 The worker is 2, the range is 2 End threading """
2.6. 线程锁
当前线程通过对某些资源上锁,其他视图获取该资源的线程就会被阻塞,直到当前线程释放该资源
import threading
lock = threading.Lock()
def worker(n):
for i in range(3):
# 方法一
# lock.acquire()
# print(f'The worker is {n}, the range is {i}')
# time.sleep(random.random())
# lock.release()
# 方法二
with lock:
print(f'The worker is {n}, the range is {i}')
time.sleep(random.random())
threads = []
for n in range(3):
threads.append(threading.Thread(target=worker, args=[n]))
print('Start threading')
for t in threads:
t.start()
print('End threading')
"""
Start threading
The worker is 0, the range is 0
End threading
The worker is 1, the range is 0
The worker is 1, the range is 1
The worker is 1, the range is 2
The worker is 2, the range is 0
The worker is 0, the range is 1
The worker is 0, the range is 2
The worker is 2, the range is 1
The worker is 2, the range is 2
"""注:
- 线程锁应该慎用,因为会使程序的效率变低,而且还会出现死锁现象。例如下面几种情况都容易造成死锁
- 上锁期间出现异常,锁将不会释放,造成死锁。
- 嵌套锁,例如,a线程中A锁对B锁上锁,b线程中B锁对A锁上锁,则容易造成死锁。
- 其他具有上锁功能的方法(使用方法同
threading.Lock,都有对应的acquire()和release()方法):
threading.RLock,循环锁,可对自身上锁threading.Semaphore,信号锁,具有计数功能,可以用于制作线程池threading.Condition,默认是一个RLock循环锁,一般用于进行挂起操作,后面会介绍到
2.7. 挂起
从作用上来看,挂起跟阻塞的含义使相似的,都是使线程暂停运行。
但从使用行为来看,两者的差异是很大的。
- 阻塞对于暂停方是被动的,即当前线程使其他线程进入暂停,所以阻塞是可以由当前线程主动解开的,且其释放CPU,不释放内存;
- 挂起对于暂停方是主动的,即当前线程主动进入暂停,所以当前线程必须由其他线程解开,且其释放内存,不释放CPU。
基于挂起的特点,挂起常用于线程间的通信,经典的例子就是”生产者-消费者“结构
import threading
import random
import time
cond = threading.Condition()
product = None
def consumer():
global product
if cond.acquire(): # 必须加上
while True:
if product:
print(f'consume product')
product = None
cond.notify()
cond.wait()
time.sleep(random.random())
def producer():
global product
if cond.acquire(): # 必须加上
while True:
if not product:
product = 1 # 生产
print(f'product product')
cond.notify()
cond.wait()
time.sleep(random.random())
t1 = threading.Thread(target=consumer)
t2 = threading.Thread(target=producer)
t1.start()
t2.start()
"""
product product 1
consume product 1
product product 1
consume product 1
...
"""
wait()和notify()必须通过acquire()方法拿到锁后才能使用
3. concurrent
多线程池package,对threading的进一步封装
这个对于很多多线程的行为没有太多的封装,所以要实现如挂起等行为,还是得调用
threading的方法
3.1. 创建及启动
子线程一创建就会被启用
from concurrent.futures import ThreadPoolExecutor
def worker(n):
for i in range(3):
print(f'The worker is {n}, the range is {i}')
time.sleep(random.random())
pool = ThreadPoolExecutor(max_workers=2)
print('Start threading')
# 方法一
# 注:方法一只能应用于数据并行的情况,即只有一个worker方法,如果是方法并行的情况,即有多个worker方法,得用方法二
# threads = pool.map(worker, range(3))
# 方法二
threads = []
for n in range(3):
threads.append(pool.submit(worker, n))
print('End threading')
"""
Start threading
The worker is 0, the range is 0
The worker is 1, the range is 0
End threading
The worker is 0, the range is 1
The worker is 0, the range is 2
The worker is 1, the range is 1
The worker is 1, the range is 2
The worker is 2, the range is 0
The worker is 2, the range is 1
The worker is 2, the range is 2
"""设置的线程池只有2个,但有3个worker,所以2号worker只能等线程池空闲出来后才运行
3.2. 获取返回值
# 方法一的获取返回值
for t in threads:
print(t)
# 方法二的获取返回值
for t in threads:
print(t.result())
"""
Start threading
The worker is 0, the range is 0
The worker is 1, the range is 0
The worker is 1, the range is 1
The worker is 0, the range is 1
The worker is 0, the range is 2
The worker is 1, the range is 2
The worker is 2, the range is 0
The worker is 2, the range is 1
The worker is 2, the range is 2
End threading
"""由于concurrent没有阻塞的方法,虽然这个方法只是用于返回当前线程的值,但由于返回值得时候一般就是线程结束的时候,所以可以将其当成阻塞的方法使用
4. references
https://docs.python.org/zh-cn/3/library/threading.html
https://docs.python.org/zh-cn/3/library/concurrent.futures.html



