搜索树一般是为了优化查询操作的数据结构,一般树的本身也会是一棵排序树。
搜索问题一般已知一个序列,输入一个元素,输出该元素在序列中的下标。
1. 堆
实现代码传送门
1.1. 定义
堆(Heap)是专门为了优化查询最值而设计出来的完全二叉树。
特性
堆的主节点大于/小于其子节点。
种类
如果主节点比子节点的值都小就是小根堆,即,
(根 < 左) & (根 < 右),反之,主节点比子节点的值都大就是大根堆。优点
可以快速地找出一棵树的最大值或最小值。所以堆一般只查询其根节点,并不关心其他节点的情况。
由于堆是一棵完全二叉树,数据紧密相连,一般使用顺序表的形式存储(其实其他二叉树也可以存储为顺序表形式,只是堆特别适合用顺序表进行操作而已),不用存储指针域,所以可以节省内存空间。
缺点
因为左右孩子是无序的,所有无法比较左右孩子的大小,所以只能用来查询最大/最小值。
堆的构建/查询其实都是插入/删除节点的操作,所以,每次的构建/查询都会改变树的结构,用于对树的改变的开销很大。
应用场合
堆常常被当做优先队列使用,即,队列中元素出栈的顺序是按照元素的优先权大小,而不是元素入队的先后顺序。
下面以小根堆为例。
1.2. 构建/插入
输入
任意数组序列
流程
堆的构建其实就是对输入数组中的每个元素逐个插入树中。所以下面只介绍非空树的插入流程:
- 把插入元素拼接到堆尾。把该元素作为当前节点。
- 比较当前节点和其父节点的大小。
- 如果当前节点小于父节点,则将当前节点和父节点的值对换,并把父节点作为当前节点。
- 重复步骤2~3,直到当前节点不小于父节点,则插入成功。
例子
输入数组为 [8, 9, 2, 6, 4, 5, 3, 1, 10, 7] ,构建的小根堆如下:
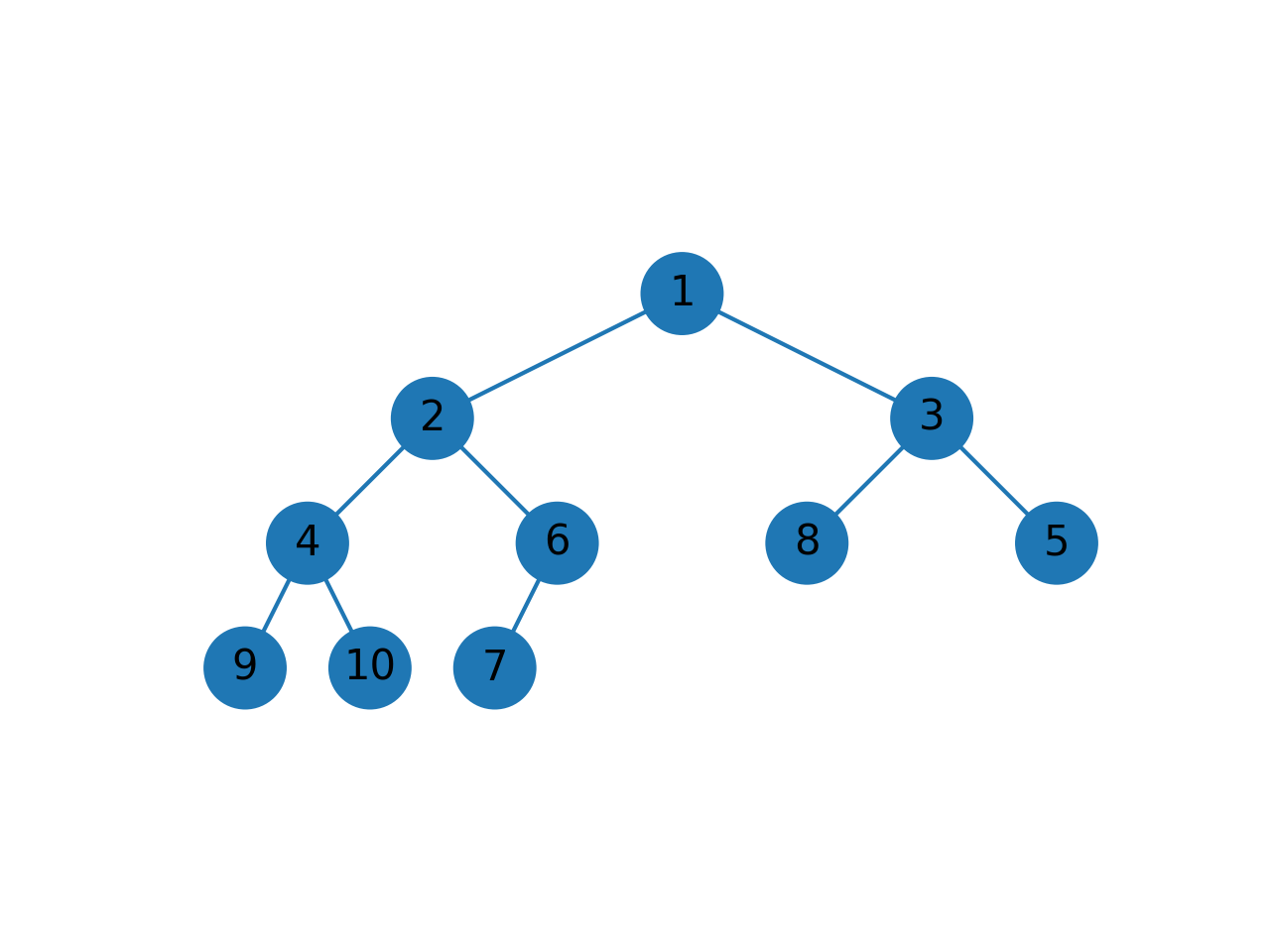
1.3. 查询/删除
堆的查询其实就是返回并删除树的根节点。下面只介绍删除重构的流程(堆的重构又称筛运算,因为其流程为把大的元素漏下去,把小的元素给筛选出来。):
- 把堆尾元素的值赋给堆头元素并删除堆尾元素。把根节点作为当前元素。
- 比较当前节点的左右节点,取其中节点值较小的节点。
- 比较当前节点和步骤2中得到的较小的节点。
- 如果当前节点值较大,则交换两个节点的值,并把步骤2中返回的节点作为当前节点。
- 重复步骤2~5,直到,当前节点为叶子节点或者当前没有进行交换,则删除完毕。
例如,上诉例子的从小到大出队序列为: [1 2 3 4 5 6 7 8 9 10]
2. 二叉搜索树
实现代码传送门
2.1. 定义
二叉搜索树(Binary Search Tree,BST)是专门为了优化排序查询设计出来的二叉树。
特性
搜索树类似于堆,但有一些区别。二叉搜索树中,左孩子小于根节点小于右孩子,即,
左 < 根 < 右。可以证明(由于篇幅有限,这里就不展开证明,详情见算法导论二叉搜索树一节),树的期望高度为 \(O(\log n)\)
优点
二叉搜索树的精妙之处在于,其中序遍历是一个有序序列。只需对树进行中序遍历就实现对输入数据的排序输出。
缺点
如果输入序列是有序序列,此时二叉树会变成单链二叉树(这是是一个特例,一般算法的平均情况接近于最坏情况,但二叉搜索树的平均情况接近于最优情况),此时会严重地浪费查询的时间和存储的空间资源。
应用场合
数据量大,查询次数多的场合。
2.2. 构建/插入
输入
任意数组序列
流程
二叉搜索树的构建其实就是对输入数组中的每个元素逐个插入树的叶子节点中。所以下面只介绍非空树的插入单个元素的流程:
- 把根节点作为当前节点。
- 比较插入元素和当前节点的大小,如果较小,则把左节点作为当前节点,反之,则把右节点作为当前节点。
- 循环重复步骤2,直到插入元素插入到叶子节点,插入完毕。
例子
输入数组为 [8, 9, 2, 6, 4, 5, 3, 1, 10, 7] ,构建的二叉平衡树如下:
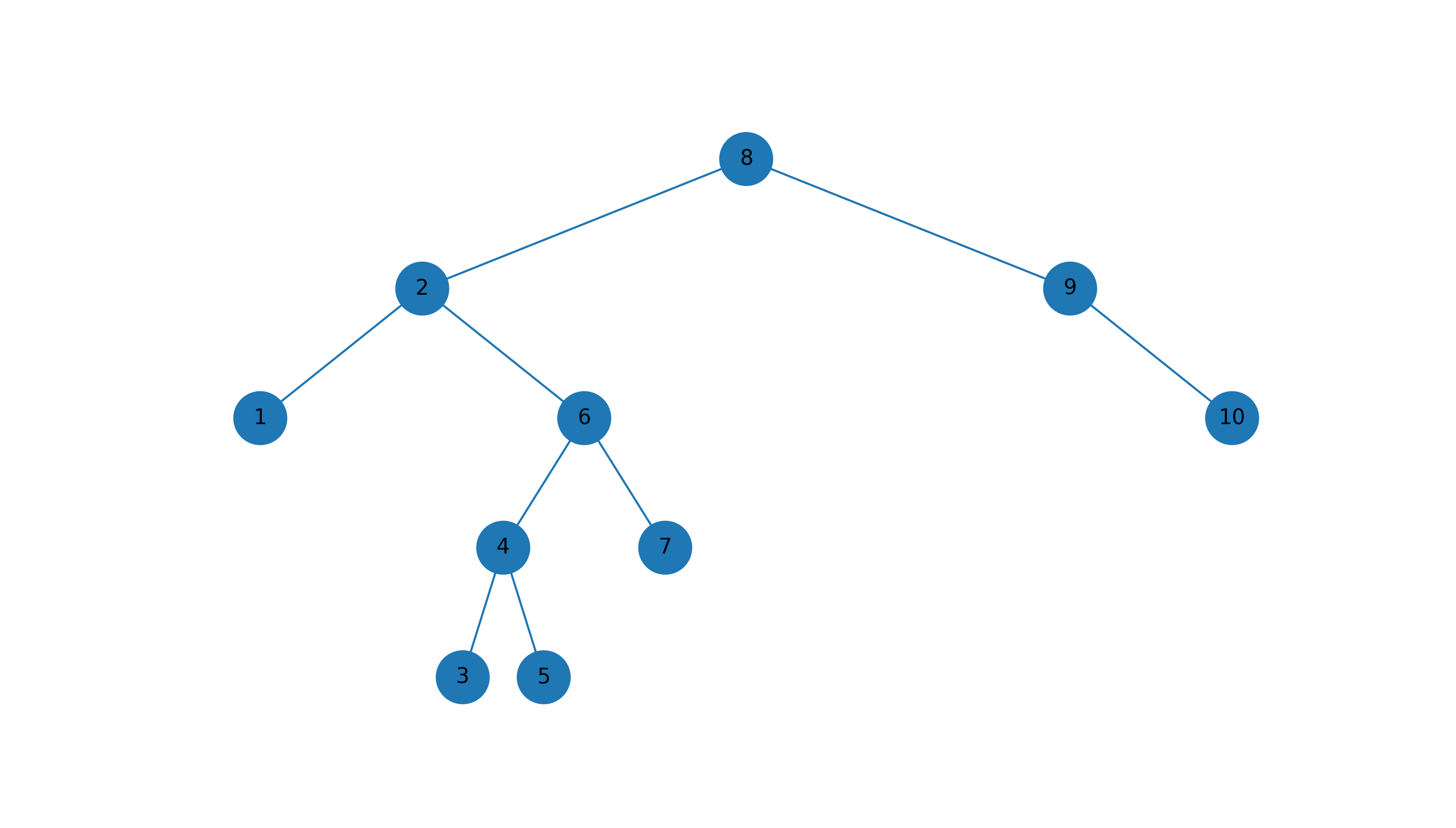
2.3. 删除
- 查找需要删除的值在树中的位置,并记录其父节点。然后判断需要删除的节点的位置状态。
- 如果待删除节点位于叶子节点,则直接删除。
- 如果待删除节点只有左/右子树,则把左/右子树整个移动到其父节点下,代替待删除的节点,子承父业。
- 如果待删除节点p左右双全,则找待删除节点前驱节点s(也可以找后序节点,与后面的流程相反即可),中序前驱节点为当前节点的左子树的最右下角的节点。如果s直接为p的左节点(说明s没有右节点),则直接把s整棵树移动代替p;否则,先把s的值赋给p,然后将s的父节点的右指针指向s的左子树(这里s原先一定是其父节点的右节点)。
- 删除完毕。
3. 平衡二叉树
实现代码传送门
3.1. 定义
平衡二叉树(Self-Balanced Binary Tree)是对二叉搜索树的改进。
特性
因为这也是一种二叉搜索树,所以也会满足二叉搜索树的特性。
和二叉搜索树不一样的是,平衡二叉树有4份内存空间——数据域、左指针、右指针、平衡因子
种类
AVL树(名字来源于其发明者G.M. Adelson-Velsky 和 E.M. Landis)是其中一种平衡二叉树,但一般也把AVL树等价于平衡二叉树。AVL树的平衡因子为左子树和右子树高度之差的绝对值。是一种完全的“平衡”二叉树。
红黑树(Red Black Tree)也是一种平衡二叉树。红黑树把平衡因子用来存储“颜色”。红黑树只要求部分平衡,认为任何不平衡都可以在3次旋转之内解决。所以(证明省略),在节点删除的时候,红黑树的开销更小。故红黑树是功能、性能、空间开销的折中结果(囿于篇幅,这里也不展开说明了)。
由于维护高度平衡所付出的代价比从中获得的效率收益还大,故而实际应用中,红黑树用的比较多。
优点
对于任意输入序列,树的高度恒为 \(O(\log n)\)
缺点
平衡二叉树的插入和删除都是递归的修改经过路径上的节点信息,资源消耗较大。
应用场合
适用于增删次数少,查询次数多的场合。
下面以AVL树为例。
3.2. 创建/插入
输入
任意数组序列
流程
跟上面一样,下面只介绍插入单个元素的流程。因为需要记录插入的路径,像二叉搜索树那样使用循环比较麻烦,所以下面只介绍递归的方法。
- 递归地比较插入元素和子节点的大小,插入元素。
- 找到插入位置后,递归地沿路径返回修改每个节点的平衡因子(其他没有经过的节点的平衡因子是不会受到影响的)。这里,为了减少重复运算,每个节点的平衡因子改为保存当前节点的高度。
- 比较当前节点的左右节点的高度差,如果绝对值大于1,则说明当前节点失衡,在保证中序序列不变的情况对树进行旋转变换配衡。有以下四种情况:
- 当插入节点位于当前节点的左节点的左子树(ll型)时,需要进行右旋操作(其实我更喜欢用顺时针旋转这个说法),即把
bn.left.left <- bn.left <- bn变为bn.left.left <- bn.left -> bn,具体的节点操作如下图。 - 当插入节点位于当前节点的右节点的右子树(rr型)时,需要进行左旋操作(逆时针旋转),
bn -> bn.right -> bn.right变为bn <- bn.right -> bn.right.right。 - 当插入节点位于当前节点的左节点的右子树(lr型)时,先对
bn.left进行左旋变成ll型,再对bn进行右旋。 - 当插入节点位于当前节点的右节点的左子树(rl型)时,先对
bn.right进行右旋变成rr型,再对bn进行左旋。 - 当递归地把路径上所有的节点的平衡因子都更新完后,插入结束。
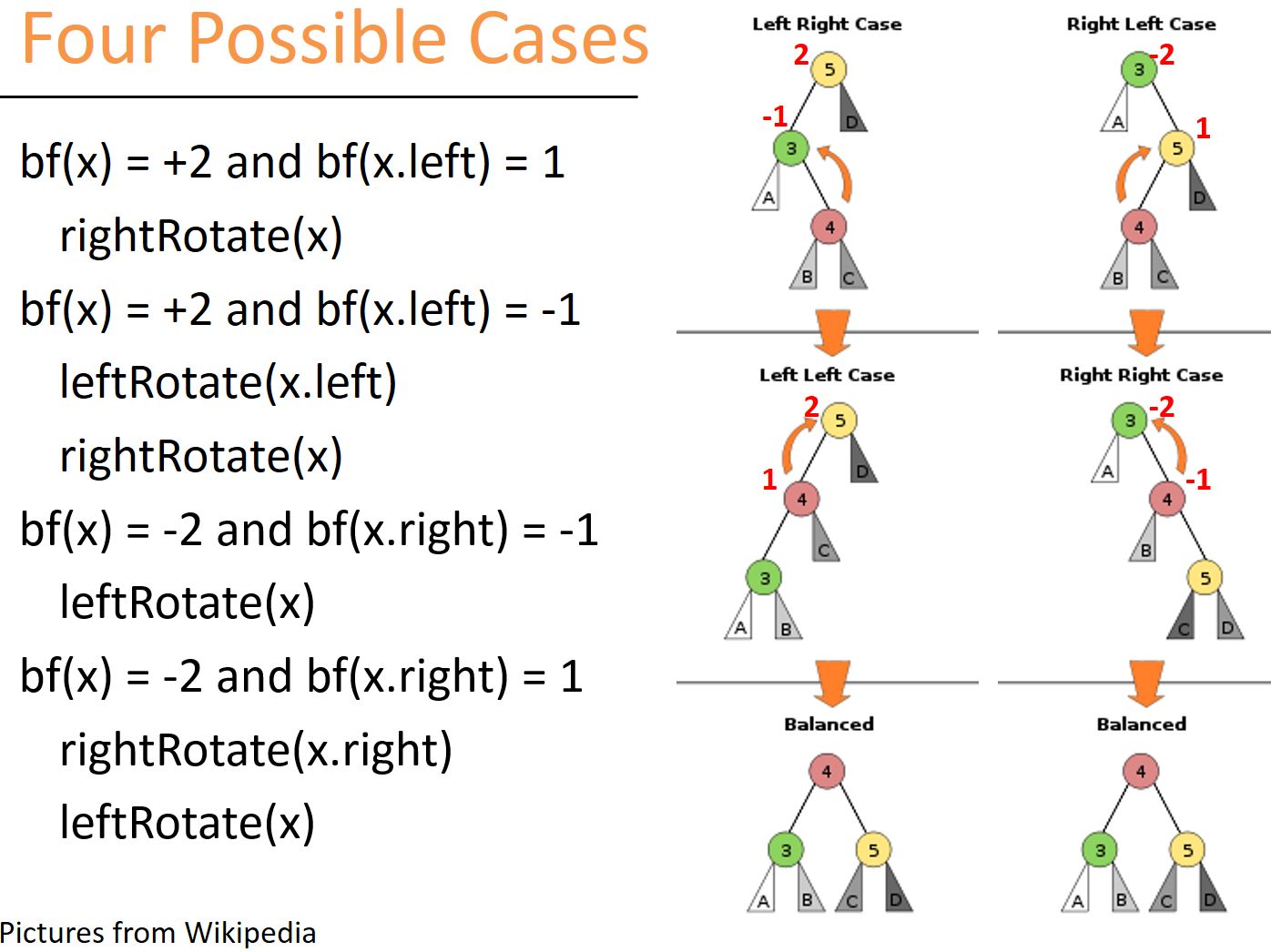
例子
输入数组为 [8, 9, 2, 6, 4, 5, 3, 1, 10, 7] ,构建的平衡二叉树如下:
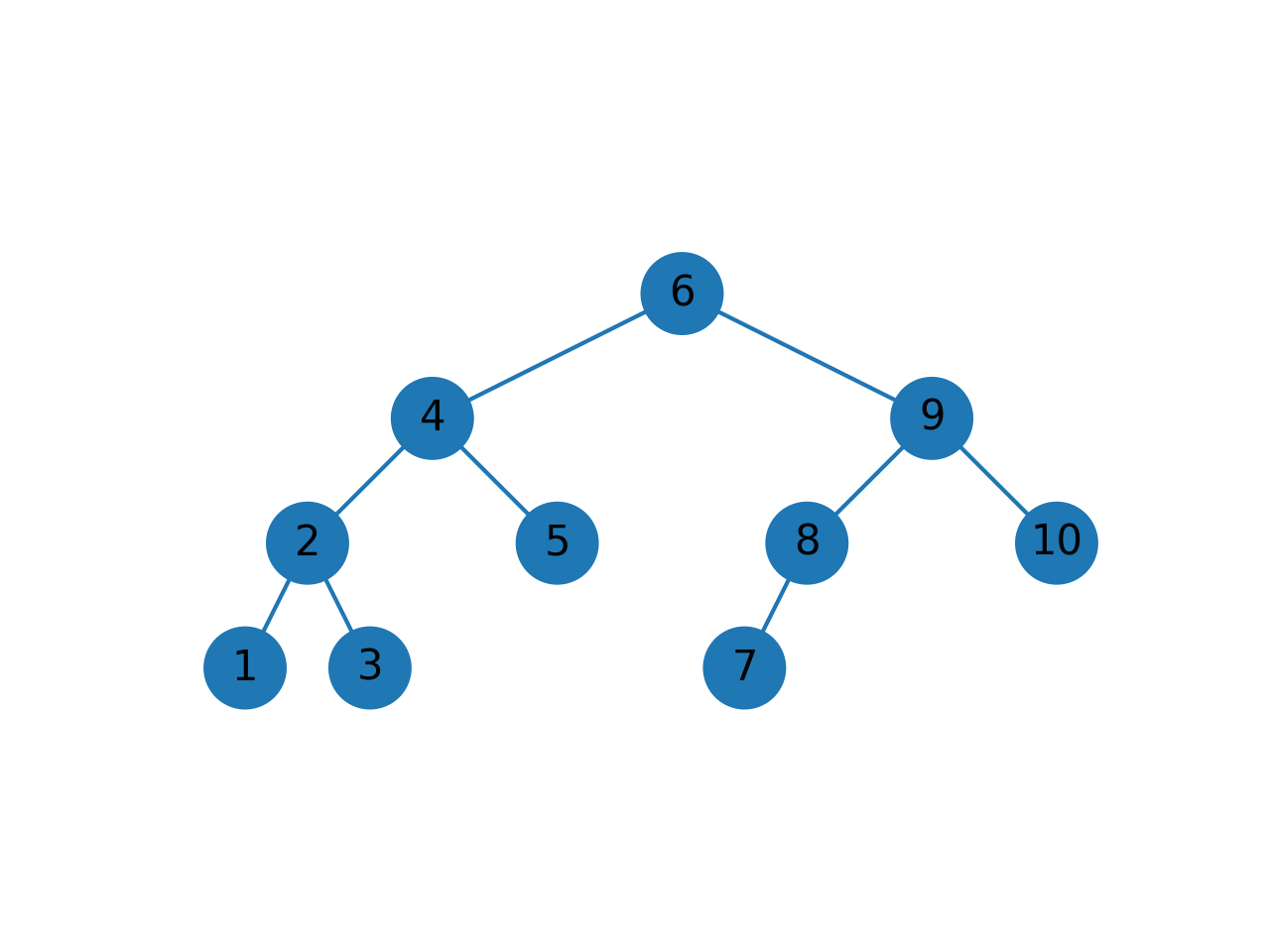
3.3. 删除
删除节点也可能导致AVL树的失衡,实际上删除节点和插入节点是一种互逆的操作:
- 删除右子树的节点导致AVL树失衡时,相当于在左子树插入节点导致AVL树失衡。
- 删除左子树的节点导致AVL树失衡时,相当于在右子树插入节点导致AVL树失衡。
另外,AVL树删除节点时有一个小trick——找到需要删除的节点后,我们用其前驱或后继节点的值代替当前节点的值,然后把要删除的值替换为前驱或后继的值,继续递归向下删除。
4. 哈希树
实现代码传送门
4.1. 定义
哈希树(Hash Tree)一种是解决哈希冲突的树
特性
- 基于质数分辨定理,即N个不同的质数对可以区分两个不同的整数(具体证明过程可以参考这里)。10个最小连续的质数即可分辨约64亿个整数。
- 非排序性,哈希树不支持排序,没有顺序特性。
- 为了避免结构的调整带来的额外消耗,哈希树设计成一个单向增加的结构,即随着所需要存储的数据量增加而增大,但不会随着数据的减小而减小。
优点
哈希树的结构是动态的,也不像某些哈希算法那样需要长时间的初始化过程,只需要初始化根结点就可以开始工作。哈希树也没 有必要为不存在的关键字提前分配空间。
查找迅速,最多只需要10次取余和比较操作,就可知道这个对象是否存在。哈希树的查找次数和元素个数没有关系。
结构不变,哈希树在删除的时候并不做任何结构调整。常规树结构在增加元素和删除元素的时候都要做一定的结构调整。
缺点
- 创建哈希树会耗时较长
- 在最坏的情况下,内存会呈爆炸式增长
应用
哈希树可以广泛应用于那些需要对大容量数据进行快速匹配操作的地方。例如:数据库索引系统、短信息中的收条匹配、大量号码路由匹配、信息过滤匹配。
4.2. 创建/插入
输入
序列集合
流程
由于输的构建就是将输入集合中的元素一个一个地插入,故下面只介绍一个元素插入的流程
- 遍历质数表,从根节点开始进行插入操作。对插入元素转换为整型。
- 设当前节点为
p,插入元素为i,遍历的质数为k,则有 \(m=i \% k\) - 如果
p的子节点域为空,则初始化k个空指针。然后查询p的第m个指针,如果该指针为空,则创建一个值为i的节点,并将该指针指向该节点,插入成功;如果该指针指向一个空节点,则将该节点的值设为i,插入成功;否则,则遍历下一个质数,把该指针指向的节点作为当前节点,重复步骤2~3
例子

4.3. 查询
查询的流程和插入的流程大致相同,只需将插入流程中的步骤3改为以下即可:
- 如果
p的子节点域为空或p的第m个指针为空,则该元素不存在;如果该指针指向节点值与待查找的元素的值相同,则该元素存在;否则,则遍历下一个质数,把该指针指向的节点作为当前节点,重复步骤2~3
4.4. 删除
删除的流程就是将查询待删除的元素得到的节点的值置空即可。
Easy job, isn't it?



