1. 优缺点
优点:
- 适合构建大规模抓取项目,如搜索引擎等
- 异步处理请求的速度快,这也是scrapy最大的优点
- 已经内置各种优化机制,例如自动调节爬取速度、响应失败重试等机制
缺点:
- 高度完善是一个双刃剑,这意味着提供给编程者的自由度很低
- 如果只是想爬少量网站,略为牛刀小用,有些鸡肋
2. 工作原理
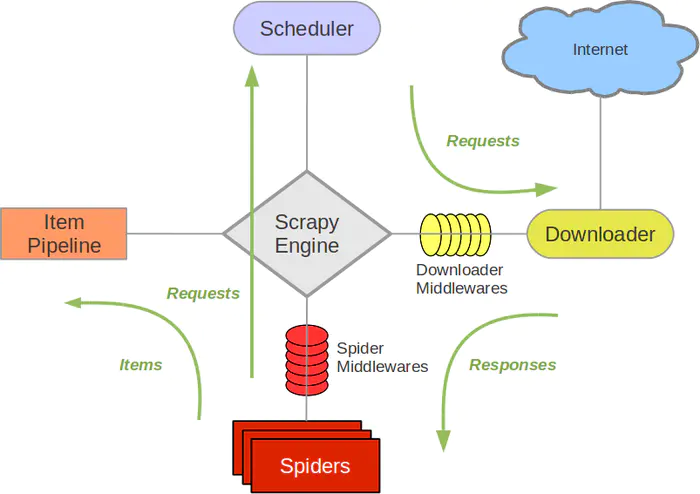
- spider通过yield将request发送给engine
- engine对request不做任何处理发送给scheduler
- scheduler对收到的request入队处理,然后顺序出队生成request交给engine
- engine拿到request,通过middleware发送给downloader
- downloader通过网络请求获取到response之后(这是异步进行的,即所有网络请求都是可以并发地产生的,同时,如果请求失败时会重新进行请求),又经过middleware发送给engine
- engine获取到response之后,返回给spider,spider的parse()方法对获取到的response进行处理,通过callback解析出items或者requests
- 将items或者request通过yield重新发送给engine
- engine获取到items或者request,将items发送给ItemPipeline,将request发送给scheduler
- 当所有部件中不存在工作流时,程序终止
除了spider和pipeline,其他功能部件scrapy都已经实现了,而pipeline可以不做修改,其功能可以直接在spider中实现,所以最终我们只需要编写spider中的文件即可。最后,spider文件的编写最重要就是搞定yield、callback和parse()方法
3. 创建项目
scrapy startproject scrapy_test
cd scrapy_test
scrapy genspider test [domain]4. 文件架构
.
├── scrapy.cfg # 项目的配置文件,存放的目录被认为是项目的根目录
└── scrapy_test # 该项目的python模块。在此放入代码(核心)
├── items.py # 项目中的item文件。(这是创建容器的地方,爬取的信息分别放到不同容器里)
├── middlewares.py # 中间件
├── pipelines.py # 项目中的pipelines文件
├── settings.py # 项目的设置文件。(基础参数的设置,例如,文件头、编码格式等)
└── spiders # 放置spider代码的目录。(放爬虫的地方)
└── test.py5. settings文件配置
一些常用的设置如下
BOT_NAME # 即headers中的User-Agent,默认为爬虫的名字
CONCURRENT_ITEMS # pipeline中同时处理(每个response的)item的最大值,默认100
CONCURRENT_REQUESTS # downloader 并发请求的最大值,默认16
CONCURRENT_REQUESTS_PER_DOMAIN # 对单个网站进行并发请求的最大值,默认8
CONCURRENT_REQUESTS_PER_IP # 对单个IP进行并发请求的最大值,注意,该值会与CONCURRENT_REQUESTS_PER_DOMAIN冲突,冲突时,优先使用该值,默认0,即无限制
DEFAULT_REQUEST_HEADERS # 发送请求的headers
DEPTH_LIMIT # 爬取网站最大允许的深度值,默认0,即无限制
DEPTH_PRIORITY # 根据深度调整request优先级,默认0
DEPTH_STATS # 是否收集最大深度数据,默认True
DEPTH_STATS_VERBOSE # 是否收集详细的深度数据,默认False
DNSCACHE_ENABLED # 是否启用DNS内存缓存,默认True
DOWNLOAD_DELAY # 下载同一个网站下一个页面前需要等待的时间,单位s,默认0
DOWNLOAD_TIMEOUT # 等待超时,默认180
DOWNLOAD_MAXSIZE # 最大响应文件大小,默认1024MB
REDIRECT_MAX_TIMES # 最大重定向次数,默认20
ROBOTSTXT_OBEY # 是否遵循robots.txt协议,默认True6. spiders文件编写
下面是 test.py中一段最简单的请求响应的伪代码
import scrapy
class TestSpider(scrapy.Spider):
name = 'test' # 爬虫文件的名字,不能修改,默认已经填好,不用管
start_urls = ['http://www.example.com/'] # 爬虫开始时,将列表中的每个url都生成一个Request对象,推送给engine
def parse(self, response): # 某种程度上说,是我们程序的主入口
do_something(response) # 对response进行一些处理
# 如果不再产生新的请求,下面的语句可以直接跳过
new_url = extract_url_from_response() # 元素定位获取新的url
yield scrapy.Request(url, callback=do_something) # 推送给engine新的Request对象,download获取新的Response对象后调取do_something方法,并传入该Response对象
def do_something1(self, response):...
def do_something2(self, response):...6.1. 发送请求
发送请求即yield一个Request对象,该对象可用的参数如下:
Request(url[, callback, method='GET', headers, body, cookies, meta, encoding='utf-8', priority=0, dont_filter=False, errback])
6.2. 接收响应
download接收到响应后返回一个Response对象,该对象可用方法如下:
response.body # 返回网页html的字节流,byte类型
response.body_as_unicode() # 等价于 response.body.decode(response.encoding)
response.encoding # 网页编码,已做自动探测优化
response.xpath(query) # 等价于selector.css(query)
response.css(query) # 等价于selector.xpath(query)6.3. 元素定位
scrapy中定义了一个Selector对象专门用于元素定位,scrapy仅支持css、xpath和re方式进行元素定位
from scrapy.selector import Selector
# 获取selector对象
selector = Selector(text=text)
selector = Selector(response=response)
# 返回一个 SelectorList 对象,Selector对象可以使用的方法,SelectorList对象大部分也可以使用
selector_list = selector.css(query)
selector_list = selector.xpath(query)
# 获取文本数据
selector.extract()
selector_list.extract() # 所有匹配成功的文本
selector_list.extract_first(default=None) # 只获取第一个匹配成功的文本
# 如果使用re方式,则直接返回文本列表
selector.re(regex)
selector.re_first(regex)7. 命令行调试
scrapy crawl <spider> # 使用spider进行爬取
scrapy check [-l] <spider> # 运行contract检查
scrapy list # 列出当前项目中所有可用的spider
scrapy fetch <url> # 使用Scrapy下载器(downloader)下载给定的URL
scrapy view <url> # 在浏览器中打开给定的URL
scrapy settings [options] # 获取Scrapy的设定
scrapy runspider <spider_file.py> # 在未创建项目的情况下,运行一个编写在Python文件中的spider8. references
https://docs.scrapy.org/en/latest/
https://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/tutorial.html



