seq2seq基础原理笔记
transformer是一种基于seq2seq结构的序列生成神经网络。
1. 输入输出
训练输入:
编码器 \[ X=\{x_1,\cdots , x_N\} \] 解码器 \[ X'=\{x'_1,\cdots , x'_N\} \]
其中,
- \(x\) 为编码器输入特征域,\(x_i \in \mathbb{R}^{n},i =1,2,...,N\)
- \(x'\) 为解码器输入特征域,\(x'_i \in \mathbb{R}^{n},i =1,2,...,N'\)
测试输入
编码器 \[ \hat X=\{\hat x_1, \cdots ,\hat x_{\hat N}\},\hat x_i \in \mathbb{R}^n \] 解码器 \[ \hat X'=\{\hat x'_1,\cdots , \hat x'_N\},\hat x_i \in \mathbb{R}^n \] 测试输出: \[ \hat X=\{\hat x'_2, \cdots ,\hat x'_{\hat N + 1}\},\hat x'_i \in \mathbb{R}^n \]
2. 基本定义
2017年的论文:Attention is All You Need
Transformer的基础单元是attention神经元,其取代的是RNN或CNN
对比RNN,attention的优点为,训练过程是并行计算,不像RNN只能串行计算,所以其更加适合在大规模的分布式集群中训练;还有一些文章中指出,其特征抽取能力要强于 RNN。
对比CNN,attention的优点为可以看到可以看到全局的数据,不像CNN只能通过卷积核一层一层的缩小感受野来获取全局变量。
对比上面两者,attention的缺点是需要非常大量的数据才能训练出一个效果和RNN或CNN差不多的模型。
一个经典的transformer架构如下图所示
![]()
上图中,左边是编码器,右边是解码器,下面按照数据流向,从左到右、从下往上这个顺序逐层进行分析。
2.1. 编码/解码器输入层
和经典的seq2seq网络的输入类似,解码器也需要右移一位增加一个开始标记符,这里也就不再多加阐述。
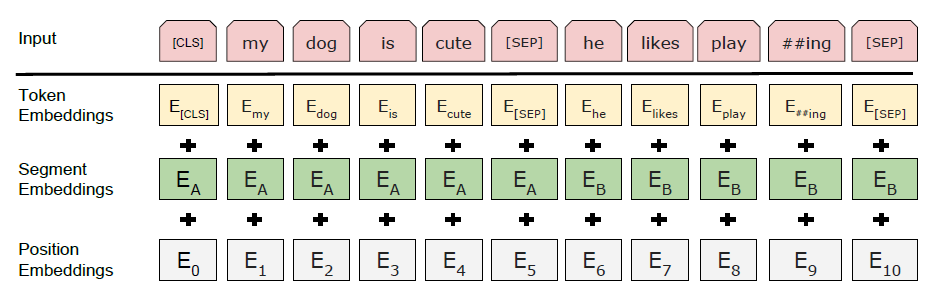
2.1.1. Embedding
就是将one-hot编码矩阵投影到语义空间中。
注:
为了避免embedding输出的权值过大,使得像位置编码这些额外的编码层的权值被忽略,有时候也会在其输出后除上一个 \(\sqrt{d_k}\)
2.1.2. Positional Encoding
由于后面接的无论是attention层,还是全连接层都是不包含时序信息的。为了解决时序预测的问题,transformer通过加入位置编码来提供时序信息。
更加具体的,第 \(p\) 个时刻的第 \(i\) 个向量的位置编码为 \[ \begin{aligned} \text{PE}_{p, 2 i} &=\sin \left(p / 10000^{2 i / d_k}\right) \\ \text{PE}_{p, 2 i+1} &=\cos \left(p / 10000^{2 i / d_k}\right) \end{aligned} \] 其中,每一时刻的位置编码的输出是一个 \(d_k\) 维的向量。
例如,下面是一个长度为50,维度为128的位置编码。
![]()
最后,将Positional Encoding的输出与embedding层的输出相加,即得到输入层的输出。
注:
使用这种编码方式的好处
可以拿到一个相对位置的编码。因为对于任意时刻的 \(PE_{p+k}\) 都可以通过 \(PE_p\) 通过以下三角变换公式得到 \[ \begin{array}{l} \cos (\alpha+\beta)=\cos (\alpha) \cos (\beta)-\sin (\alpha) \sin (\beta) \\ \sin (\alpha+\beta)=\sin (\alpha) \cos (\beta)+\cos (\alpha) \sin (\beta) \end{array} \]
从上图可以看出,序列开始的编码趋向于无序,而后面的编码趋向于周期性,所以模型会更关注序列开头的部分。
时序相近的编码相关性较大。对上面例子中的位置编码两两做内积,得到如下热力图

可以发现,其相关性随距离的减小而增大,继而起到一个类似 n-gram 的效果。
不受长度限制。对比one-hot编码,这种编码可以得到一个与embedding层输出维度相同的向量,进而更加容易做矩阵运算。
当然位置编码也不一定要使用上述的公式,也可以通过训练得到,具体的可以参考这篇论文:Convolutional Sequence to Sequence Learning
2.2. Attention层
2.2.1. Scaled Dot-Product Attention
输入包含三个变量 \(Q \in\mathbb{R}^{n\times d_k}, {K}\in\mathbb{R}^{m\times d_k}, {V}\in\mathbb{R}^{m\times d_v}\)
由于需要做点积(Dot-Product)运算,所以上述三个变量都是等长的,当然如果是一个加性(additive)的注意力层,这三个变量是可以不等长的。加性attention层的定义式: \[ \text{Attention}(Q,K,V) = \text{tanh}\left(W_1Q+W_2K\right)V \]
下面直接给出该层的定义式 \[ \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^{\top}}{\sqrt{d_k}}\right)V \] 其中,
- \(QK^{\top}\) 是为了求Q和K的相似度,用该内积矩阵作为V的权值矩阵,输出矩阵大小为 \(n \times m\)
- \(\frac{(\cdot)}{\sqrt{d_k}}\) 是为了防止内积太大,使得softmax后出来的值趋向于饱和区,使得求梯度变得困难,如果 \(d_k\) 值较小时,这一步的操作可以忽略
- \(\text{softmax}({\cdot})\) 是为了将输出权重变成一个非负且取值区间位于0到1的权值矩阵,可以理解为得到了一个近似于one hot的矩阵,n维输入中的每一维特征可以使用m维输出中的哪一个维度特征进行表示。
- \((\cdot)V\) 是为了将矩阵从 \(m\) 维空间投影到 \(n\) 维空间中,输出矩阵大小为 \(n \times d_v\),由于前面的矩阵是一个近似于one hot的矩阵,所以这一步操作可以理解为做了一次embedding操作,即Key-Value键值对查询,实现所谓的注意力的机制
2.2.2. Self-Attention
可以注意到,在transformer模型中,除了解码器中间的attention层(key和Value来自于编码器,Query来自于解码器),其余的都是Self-Attention(即\(Q=K=V\) )。
Self-Attention的优点是让网络自己寻找序列的内部联系。
对于一般的线性计算,并不具有明显的时序性。又注意到,在内积计算 \(QK^{\top}\) 中,当两个输入相同时,其相似度最高。
在自注意力计算时,有大量自相关的输入,通过softmax计算后得到同一个key值,则说明这些输入具有相似的序列结构,模型便能注意到这些相似的序列结构。
在非自注意力计算时,理论上只有编码器输入与编码器输入一样,输出相似度最高对应的key值;而如果有一个编码器输入与解码器输入不一样的输入,也能得到一个输出相似度最高对应的key值,则说明编码器输入与解码器输入某些序列结构有着强关联。
2.2.3. Mask Attention
由于attention是可以观察到全局的数据的,但真实任务中,来自于解码器的Query都是按时序输入的,这就意味着当前时刻是无法观察到后序的输入,否则就会造成数据穿越。所以需要屏蔽掉当前时候后序输入的权值。
例如,在翻译任务中,翻译的过程是顺序进行的,只有翻译了第 \(t\) 个单词,才能翻译第 \(t+1\) 个单词,
又因为这步操作需要在softmax前完成的(如果在softmax后置0,既会使得权重之和不为1,也会导致无法求导),所以需要将对应的被mask掉的权值替换成一个趋向于无穷小的负值,这样softmax后得到的这些权值就会趋向于0,达到被mask掉的效果。
例如,对一个长度为5的输入序列做mask的过程如下
![]()
注:
编码器的mask和解码器的mask是不一样的。
由于编码器的输入是允许全局观察的,所以其mask的作用是屏蔽padding的部分,其形状类似一个矩形
而编码器的输入是不允许全局观察的,所以其mask还需要屏蔽未来的时序输入,其形状类似一个三角形
2.2.4. Multi-Head Attention
注意到上面乘性的attention层是不包含超参数项(对比加性的attention包含两个超参数),也就意味着模型无法进行参数学习。
为了解决这一问题,可以引进超参数 \(W_{i}^{Q} \in \mathbb{R}^{d_k \times d_{k}'}, W_{i}^{K} \in \mathbb{R}^{d_k \times d_{k}'}, W_{i}^{V} \in \mathbb{R}^{d_v \times d_{v}'}\),让Q、K、V在进入attention层前分别做一次线性变换,即 \[ \text{head}_i = \text{Attention}(QW_i^Q,KW_i^K,VW_i^V) \] 为了使attention层学到的东西更加丰富,与卷积网络类似,叠加 \(h\) 个attention层,然后引入参数 \(W^{O} \in \mathbb{R}^{h d_{v}' \times d_v}\),再做一次线性变换,使其变为原来的attention的输出维度,即 \[ \text{MultiHead}(Q,K,V) = \text{Concat}(\text{head}_1,...,\text{head}_h)W^O \] 结构图如下
![]()
2.3. Add & Norm
该层的结构如下
![]()
其定义式如下 \[ \text { LayerNorm }(x+\text { Sublayer }(x)) \] 其中,
- add表示残差连接,借鉴了CNN的做法,可以让网络只关注当前差异的部分,可以减轻多层网络的退化问题
- norm表示Layer Normalization,借鉴了RNN,可以将每一层神经元的输入都转成均值方差都一样的,可以加快收敛
2.4. Position-wise Feed-Forward Networks
这一层就是将两个全连接层合并成一个网络层,即 \[ h_1 = \text{Relu} \left(x W_{1}+b_{1}\right) \\ h_2 = h_1 W_{2}+b_{2} \] 但需要注意的是,由于后面还有一个残差连接,所以 \(h_2\) 和 \(x\) 的维度得保持一致。
2.5. 输出层
略。
3. 一些改进
- Universal Transformers。主要特性:
- 通过引入了递归,因此在内存充足的条件下,它是图灵完备的。
- 通过引入自适应处理时间
Adaptive Computation Time(ACT),它使得不同token的迭代时间步不同。 - 训练采用
teacher-forcing策略。
- Transformer XL。主要特性:
- 取代了取语料库中最长序列的长度,作为文本序列的固定长度的做法,而将整个语料库分割成固定大小的、较短的片段
segment,然后用每个片段来训练模型,而忽略之前所有片段的信息。 - 引入递归机制和相对位置编码。
- 取代了取语料库中最长序列的长度,作为文本序列的固定长度的做法,而将整个语料库分割成固定大小的、较短的片段
4. references
https://luweikxy.gitbook.io/machine-learning-notes/self-attention-and-transformer
http://www.huaxiaozhuan.com/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/chapters/7_Transformer.html
《Attention is All You Need》浅读(简介+代码)